【AWS SAP認定試験】約1ヶ月で一発合格!合格のコツとは!? ~前編~

先日、AWS SAPの試験を受験し、無事に一発合格することができました! そこで今回は合格するためのコツや実際にどんな風に勉強を進めたのか、などをまとめていきたいと思います。 少しでもこれから受験される方の参考になれば幸いです。
目次
どんな試験なの?
試験の内容はこんな感じです。
- 試験名: AWS認定ソリューションアーキテクト-プロフェッショナル
- 試験時間: 180分
- 問題数: 75問
- 費用: 30,000円(税別)
3時間、、とってもタフな試験ですね。 当日の集中力も試されます。
そして、何と言っても1回3万円という受験費用! 気軽には受けられないですね。。
こちらに公式の試験ガイド等がありますので、一読しておきましょう。
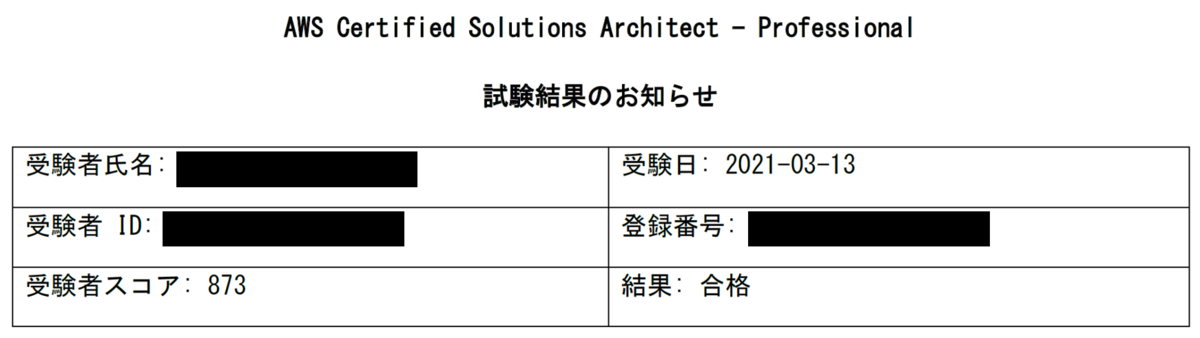
試験結果
試験本番では確証のない回答が多く、悲観値だと750点ギリギリくらいの見立てだったので、思っていたよりもスコアが取れて良かったなーという感覚です。
で、合格のコツはなんだったのさ?
先に結論ですが、私の場合はWeb問題集(aws.koiwaclub.com)の問題をひたすら解き、AWS BlackBeltで弱点を補うことが合格のコツでした!
こんな3ステップで学習サイクルをまわしてました。
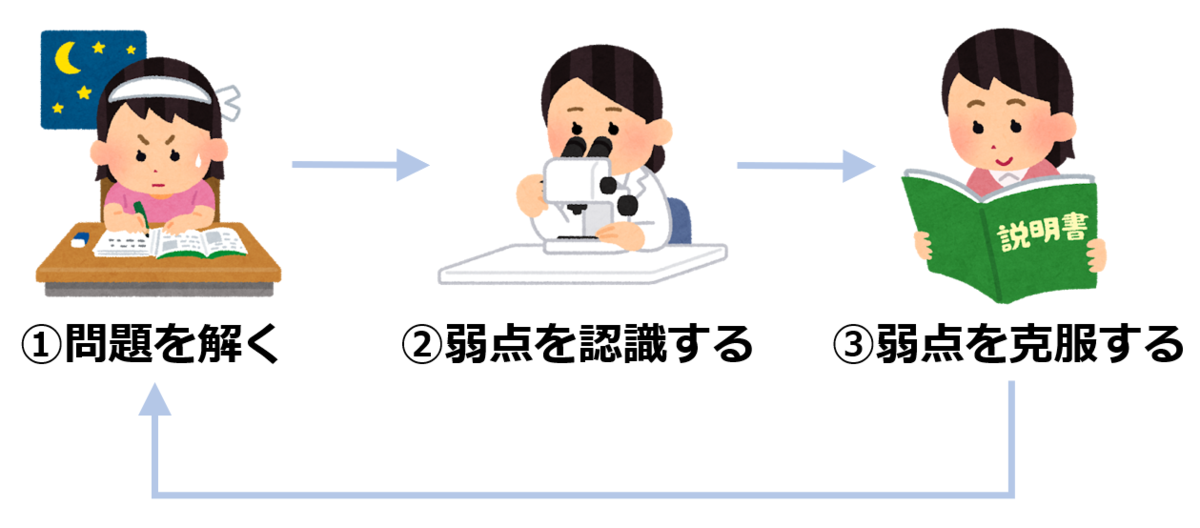
※釈迦に説法ですが、これをやったら絶対に受かるというわけではありません。悪しからず。
まずは自分に合った勉強戦略を立てよう
この3ステップに入る前に、まずはどんな勉強方法が自分に適しているのか戦略を練りました。
昨今、AWS SAPはとても有名な認定資格になったため、例えば「AWS SAP 合格」のようなキーワードでググると、良質な合格体験記がたくさん出てきます。
それらを見比べながら、自分に合った勉強戦略を考えて受験までの計画を練ることからスタートすることがポイントかと思います。
私の場合は1ヶ月で取得したかったので、全方位的な深い理解というよりは合格することを主眼におきました。
先人たちの合格体験記を見ていると「ホワイトペーパーをガッツリ読み込みました」というような方が多いですが、私の場合はそのような時間を確保する見立てがたたなかったので、読み物の時間は最小限におさえ、本番に近い問題を解く練習をするという戦略をとることに決めました。
(普段ならばじっくりと読み物をしてからじゃないと気持ち悪く感じてしまうのですが、今回はスピード重視で割り切ました・・・)
次回の記事では上述した3ステップの中身をもう少し詳しくお伝えしていければと思います。
以上。
【AWSの呼吸 肆ノ型】Amazon Forecastで 新型コロナウイルスの感染者数を予測してみる
今回はAmazon Forecastを用いて、新型コロナウイルス感染症(COVID-19)の陽性者数を予測してみたいと思います。
※あくまでAWSの機械学習サービスの勉強の一環ですので、科学的な根拠に基づいて何か提唱するような記事ではありません。
目次
「Amazon Forecast」とは?
時系列データを基に機械学習で将来の数値の予測ができるサービスです。
例えば、EC2インスタンスのキャパシティや電力の使用量の予測が可能です。
予測結果
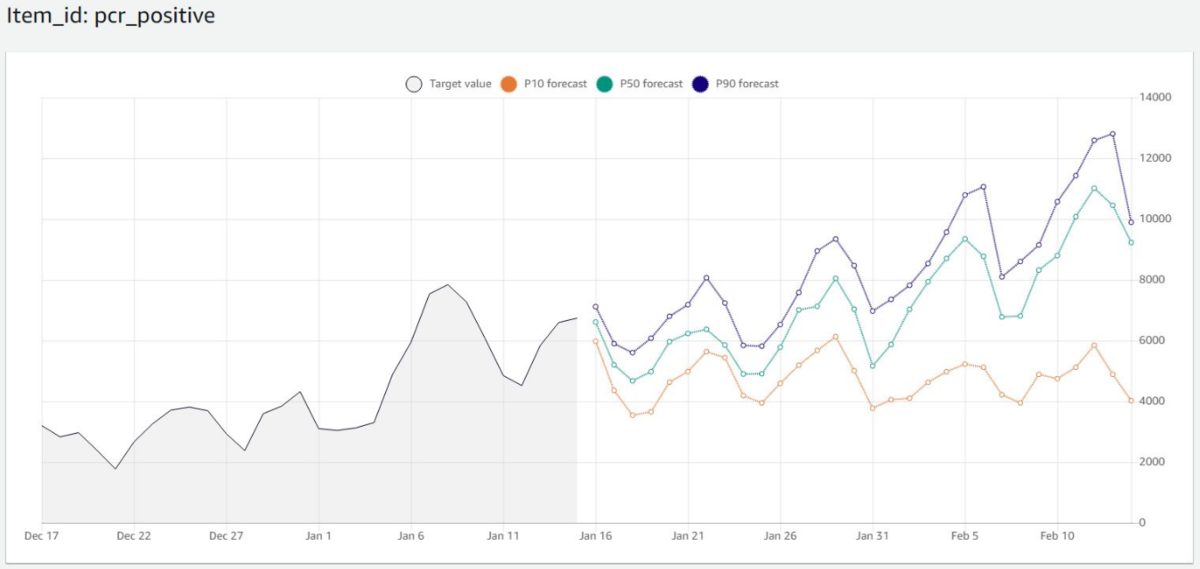
先に結果からお見せしてしまうと、こんな感じになりました。
来月には全国の陽性者数が1万人を超えるという予測です。

- P10:10パーセンタイル (下振れ値)
- P50:50パーセンタイル (中央値)
- P90:90パーセンタイル (上振れ値)
利用したデータ
- 厚生労働省が一般公開している日本国内の陽性者数のデータを利用します。
- 時系列のCSVデータです
- こちらからダウンロード可能です:オープンデータ|厚生労働省
- 今回のCSVデータの内容は以下の通りです
- 期間:2020/1/16~2021/15
- レコード数:366
- レコード内容: 日次の陽性者数
抜粋するとこんな感じのシンプルな時系列データです。
日付,PCR 検査陽性者数(単日) 2021/1/12,4521 2021/1/13,5841 2021/1/14,6598 2021/1/15,6741
Forecastで予測する期間
30日間 (2021/1/16~2021/2/14)
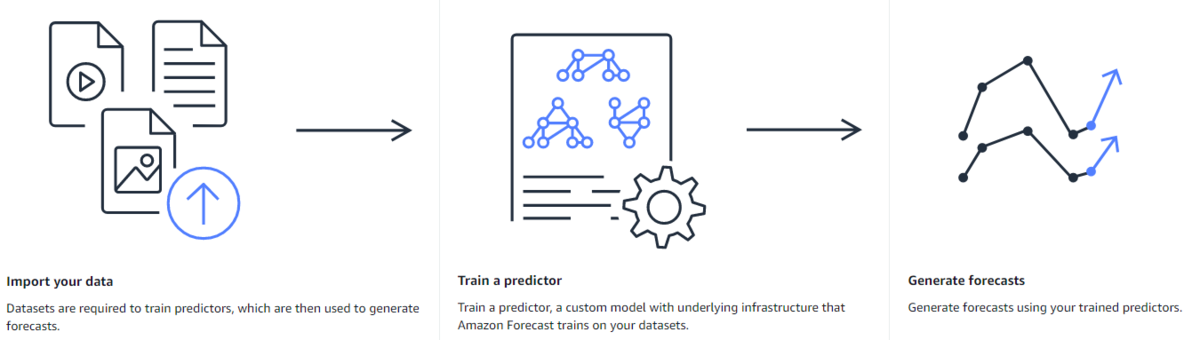
Forecastでの予測の流れ
ざっくりとデータ投入⇒学習⇒予測という流れです。
以降はこの流れにそって手順を説明していきます。
データ投入
Forecast用のデータ準備
データ加工
Forecastにデータを投入するためには事前にForecastで指定した形式にデータを加工しておく必要があります。 今回のケースでは以下の属性を含むデータとしました。
- item_id:予測対象の識別子 (string)
- timestamp:タイムスタンプ (yyyy-MM-dd形式)
- target_value:予測対象の数値 (float)
先述したCSVデータでは形式が合わないので、以下のように加工しています。(抜粋)
item_id,timestamp,target_value pcr_positive,2021-01-12,4521 pcr_positive,2021-01-13,5841 pcr_positive,2021-01-14,6598 pcr_positive,2021-01-15,6741
S3アップロード
後述の"dataset"からデータを参照できるように加工したデータを任意のS3バケットにアップロードしておきます。
datasetgroup作成
ここからいよいよForecastの設定に入ります。
AWSマネジメントコンソールから[Amazon Forecast] > [Create dataset group]を選択し、時系列データのグループを定義します。
下記の画面のように入力し、[Next]を押します。

- ①dataset group name:時系列データのグループ名
- 任意の名前でOKですが、ハイフンを使えないのでアンスコで区切る必要があります
- ②Forecasting domain:EC2キャパシティなどForecastのプリセットの時系列データのタイプ
- 今回は該当のタイプがないため、"Custom"を指定しました
dataset作成
次に時系列データの項目を定義します。
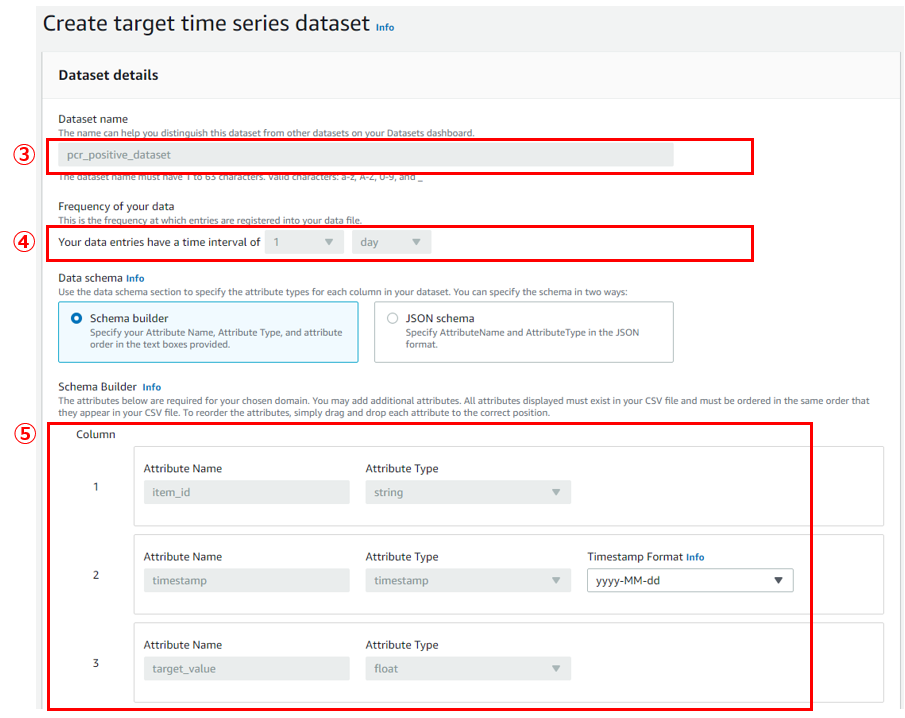
- ③Dataset name:時系列データ名
- 任意の名前でOKですが、ハイフンを使えないのでアンスコで区切る必要があります
- ④Frequency of your data:時系列データの間隔
- デフォルトで1day=日次になっているはずです
- 今回は日次データを扱うので、そのままでいきます
- ⑤Column:時系列データの列項目
- Forecasting domainがCustomの場合はitem_id,timestamp,target_valueが自動で定義されています
- TimestampFormatは元データに時間がないため、yyyy-MM-dd形式に変更しました
次に下記のようにインポートする時系列データを選択し、[Start Import]を押します。 今回のデータでは完了までに2~3分ほどかかりました。
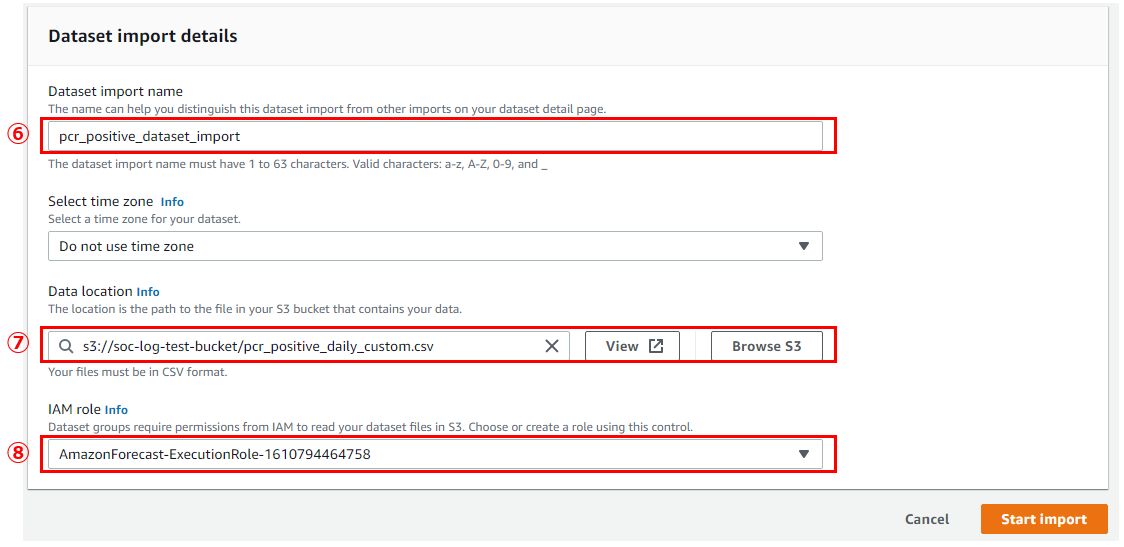
- ⑥Dataset import name:インポートする時系列データ名
- 任意の名前でOKですが、ハイフンを使えないのでアンスコで区切る必要があります
- インポート済みの名前と重複する場合はエラーで怒られます
- インポートするCSV名に合わせて名前を変えていくと管理上よいかと思います
- ⑦Data location:インポートする時系列データのS3バケット上のパス
- 先ほどアップロードしたCSVファイルのパスを指定しました
- ⑧IAM role:Forecast用のIAMロール (S3アクセス用)
- 今回はお試しなので、自動生成のロールをそのまま使ってます
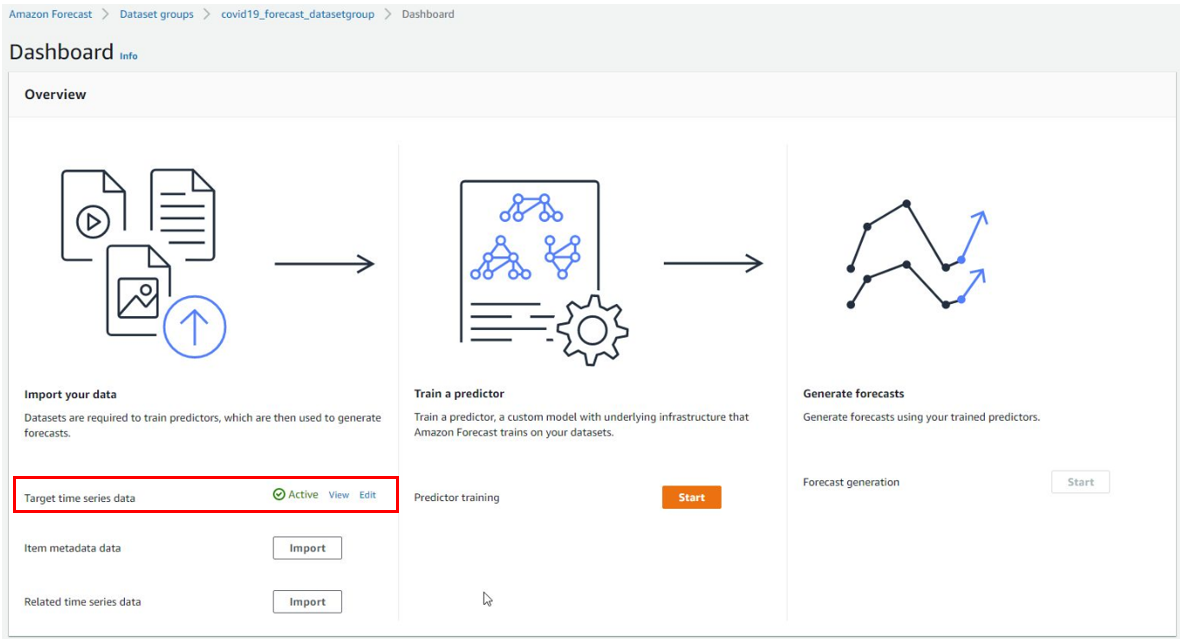
処理が完了したら下図の通りダッシュボード上のステータスが"Active"となります。
"Active"が確認できたら、"Predictor Training"の[Start]を押して次に進みましょう。
学習
predictor作成
先ほどインポートした過去の時系列データを基に予測の判断材料をつくります。
下図の通り、predictorの設定を行います。

- ⑨Predictor name:作成するPredictor名
- 任意の名前でOKですが、ハイフンを使えないのでアンスコで区切る必要があります
- ⑩Forecast horizon:予測したい期間
- 今回は予測したい期間を30日間としたいので、30を指定しました
以降、predictorの学習方法について詳細を設定していくのですが、今回はお試しなので全てデフォルト設定で次に進みます。

- ⑪Forecast horizon:学習アルゴリズム
- カスタマイズしたい人はManualで指定できるようですが、今回はお試しなのでお任せのAutomaticにしました。
他にも色々とオプションはありますが、すっ飛ばして、最後に[train predictor]を押します。
レコード数がそれほど多くないのですぐ終わるかなと思っていたのですが、完了するまでにそれなりに時間かかります。
夜に放置して次の日の朝に終わっていることを確認したので、正確な時間は分からないですが、今回のケースでは少なくとも1時間以上はかかってます。
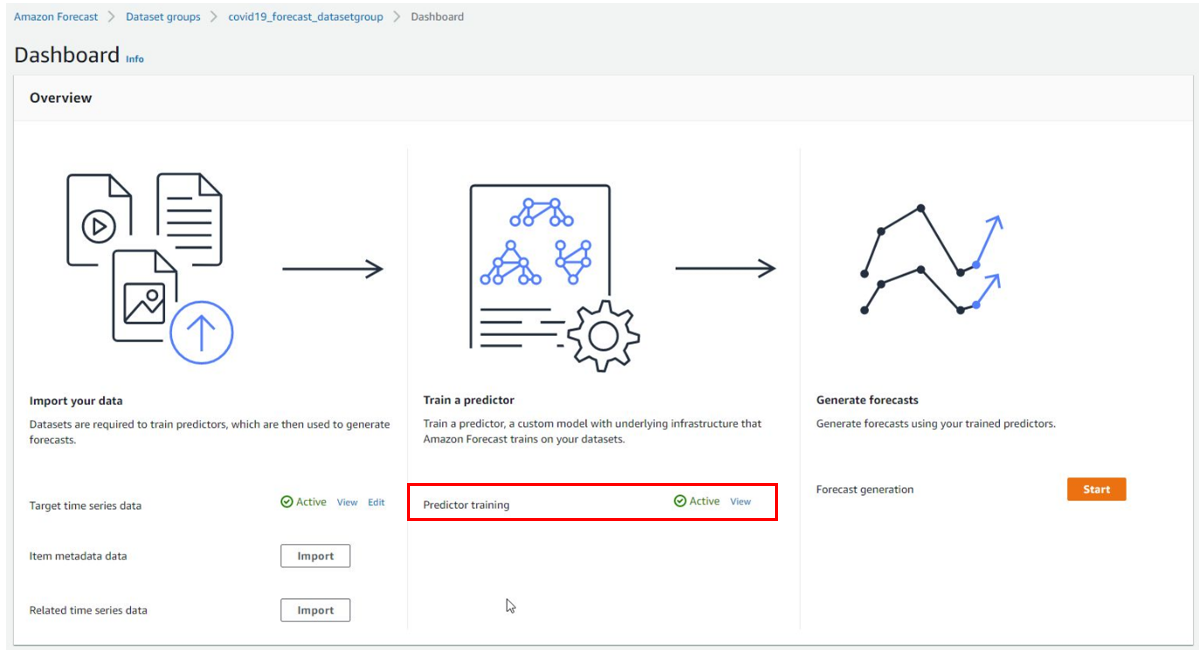
処理が完了したら下図の通りダッシュボード上のステータスが"Active"となります。
"Active"が確認できたら、"Forecast generation"の[Start]を押して次に進みましょう。
予測
forecast作成
予測の定義を作ります。
下図のforecastの詳細を指定して、[Create new forecast]を押します。
今回のケースでは完了までに30分ほどかかりました。
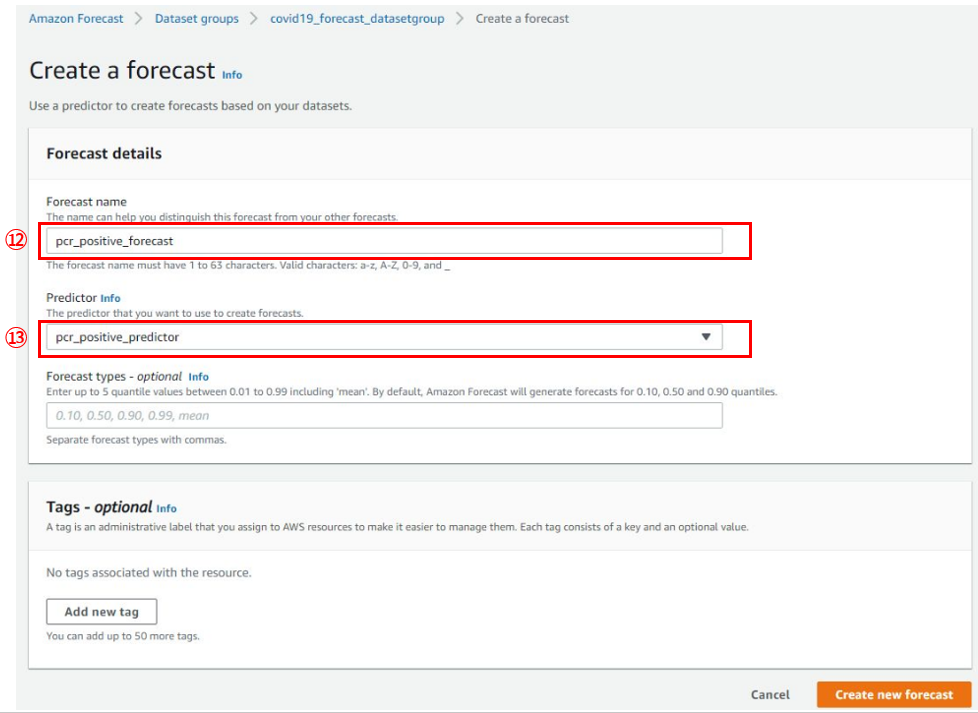
- ⑫Forecast name:作成するForecast名
- 任意の名前でOKですが、ハイフンを使えないのでアンスコで区切る必要があります
- ⑬Predictor:利用するpredictor
- 先ほど作成したpredictorを指定しました
処理が完了したら下図の通りダッシュボード上に[Lookup forecast]のボタンが現れるので、押して次に進みましょう。

予測結果の参照
ここまできたらあとは結果をグラフで表示させるだけです。
下図のように見たい項目と期間を選んで、[Get Forecast]を押します。
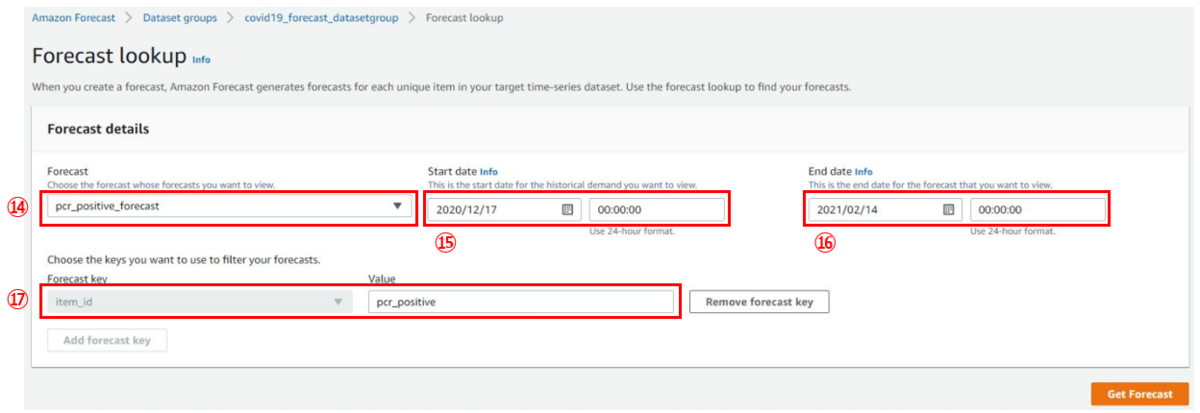
- ⑭Forecast:利用するForecast名
- 先ほど作成したものを指定します
- ⑮Start date:表示させたい開始日時
- 今回はForecast horizonで30を指定している関係で投入したデータの30日前まで指定可能になっていると思われます
- ⑯End date:表示させたい終了日時
- 今回はForecast horizonで30を指定している関係で投入したデータの30日後まで指定可能になっていると思われます
- ⑰Value:表示させたい項目
- datasetで投入したデータのitem_idの値="pcr_positive"を指定しました
すると冒頭でお見せした結果が取得できます!
参考にしたページ
以上。
【AWSの呼吸 参ノ型】AWS Client VPNでIPアドレスを制限する方法
今回はAWS ClientVPNで、IPアドレスの制限を行う方法を書きたいと思います。
ClientVPNを使いたいけど、自社等のセキュリティポリシー的にアクセス元を制限しないと使えないという方はぜひ活用してみてください。
目次
やりたいこと
AWS ClientVPNに接続する際に接続元のIPアドレスが許可されたものでなければ、接続を拒否する。
IP制限を行う方法
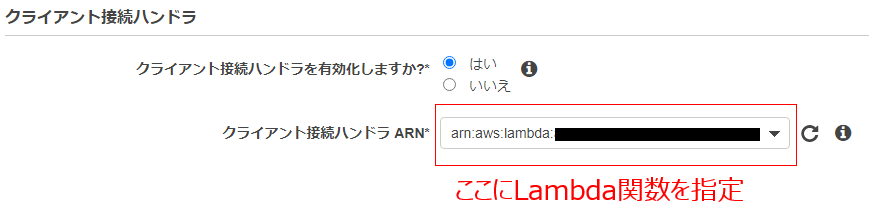
- 2020年11月にサポートが開始されたクライアント接続ハンドラを使って実現します
- IP制限の処理をLambdaで実装し、クライアント接続ハンドラに割り当てます
- するとClientVPNエンドポイントに接続があった際にClientVPN側でLambdaを呼び出してチェックしてくれます
Lambda設定
まずはクライアント接続ハンドラに割り当てるためのLambda関数を作成します。
Lambda関数の作成
今回はこんな感じで作りました。
その他も利用中の環境に合わせてよしなに設定してください。
- ランタイム:Python 3.8
- トリガー:なし (ClientVPN側で割り当てれば指定する必要なし)
- VPC:なし
- IAMロール:自動生成されるもの
- 環境変数:許可したいIPアドレスのホワイトリスト
実装例
ポイントは"event['public-ip']"にClientVPNの接続元のIPアドレスが格納されてくるので、その値とホワイトリストを照合するところです。
照合した結果、許可されていれば"allow": にTrueを指定して、ClientVPN側に返却することで、ClientVPN側でその接続を許可してくれます。
また、今回の実装例では今後CIDRでホワイトリストを指定したくなるようなケースも見越して、ipaddressモジュールで実装してみました。 その方が単純な文字列での照合よりはIPアドレスの扱いに柔軟性が出てよいのかな思います。
import ipaddress import os def lambda_handler(event, context): # IPアドレスの判定フラグを初期化 # 許可:True / 拒否:False flag = False # 許可するIPアドレスのリストを環境変数から取得 allow_ip_list = [x.strip() for x in str(os.environ['ENV_IP_LIST']).split(',')] # 接続元のIPアドレスをClientVPNから取得 src_ip = ipaddress.ip_address(event['public-ip']) # 接続元IPが許可されているものかリストと照合 for ip in allow_ip_list: ip_nw = ipaddress.ip_network(ip) if src_ip in ip_nw: flag = True break else: flag = False # ClientVPNに結果を返却 return { "allow": bool(flag), "error-msg-on-failed-posture-compliance": "IP address is not allowed to access.", "posture-compliance-statuses": [], "schema-version": "v1" }
上記ではロギングとエラーハンドリングは割愛してます。
例えば、拒否したIPアドレスを後で把握できるようにログ出力しておくなどの実装はしておいた方がよいかもしれません。
クライアント接続ハンドラの設定
先ほど作成したLambdaをClientVPN側に設定します。
AWSマネージメントコンソールにて、[クライアント VPN エンドポイント] > [クライアント VPN エンドポイントの変更]を開きます。
([クライアント VPN エンドポイントの変更]は利用するクライアントVPNエンドポイント選択して、アクションから開けます。)
参考にしたページ
- [アップデート] 接続元 IP 制限もできるように! AWS Client VPN で クライアント接続ハンドラ機能がサポートされました | Developers.IO
- AWS SAMのLambda (Python)で環境変数で設定した値を配列で受け取る - Qiita
- ipaddress --- IPv4/IPv6 操作ライブラリ — Python 3.9.1 ドキュメント
- 特定のIPだけ許可したい時の判定方法 - thirose’s blog
- Connection authorization - AWS Client VPN
以上。
【AWSの呼吸 弐ノ型】CodeDeployでVPCエンドポイントを設定する
ついにCodeDeployがVPCエンドポイントに対応しました。
参考:「AWS CodeDeploy が VPC エンドポイントへのデプロイのサポートを開始」
CodeDeployは標準でblue/greenデプロイに対応している便利なサービスなのですが、これまでVPCエンドポイントには対応していなかったのです。
なので、例えばProxyを運用してインターネットへのアクセス制限をしているような環境では、CodeDeployエージェント側の設定ファイルを編集してProxyを指定し、Proxy側でCodeDeployのエンドポイントのURLをホワイトリストに登録するといったひと手間が必要でした。
今回のサポートを受けて、その手間から解放されます!
ということでやってみました。
目次
やったこと
基本的には公式ページ「Use CodeDeploy with Amazon Virtual Private Cloud - AWS CodeDeploy」に沿って、設定します。
CodeDeploy用のVPCエンドポイント作成
CodeDeployエージェント設定変更
IAMロール設定変更
CodeDeploy用のVPCエンドポイント作成
[VPC]->[エンドポイント]から[エンドポイントの作成]を選択し、以下の2つのVPCエンドポイントを追加します。
用途に応じてどちらか片方でもOKです。
VPC、サブネット、SGなどは利用したい環境に合わせてよしなに設定してください。
- com.amazonaws.region.codedeploy
- CodeDeployのAPIを実行する用 (create-deploymentなど)
- com.amazonaws.region.codedeploy-commands-secure
- CodeDeployエージェントがマネージャ側と通信する用
CodeDeployエージェント設定変更
上で解放されると言っておきながら、実はエージェント側で1ヵ所変更が必要です。。
「/etc/codedeploy-agent/conf/codedeployagent.yml」にて、":enable_auth_policy: "を"true"にする必要があります。(デフォはfalse)
「Use CodeDeploy with Amazon Virtual Private Cloud - AWS CodeDeploy」にさらっと書いてあるので、見落としやすいですが、これがないとVPCエンドポイントを介して動きません。
以下のように編集します。
codedeployagent.yml
:log_aws_wire: false :log_dir: '/var/log/aws/codedeploy-agent/' :pid_dir: '/opt/codedeploy-agent/state/.pid/' :program_name: codedeploy-agent :root_dir: '/opt/codedeploy-agent/deployment-root' :verbose: false :wait_between_runs: 1 :proxy_uri: :max_revisions: 5 :enable_auth_policy: true
IAMロール設定変更
CodeDeployエージェントを稼働させているEC2などの実行環境にアタッチしているIAMロールに以下のActionを追加します。 (参考リンクのテキストをコピペでもOKです。)
"Action": [ "codedeploy-commands-secure:GetDeploymentSpecification", "codedeploy-commands-secure:PollHostCommand", "codedeploy-commands-secure:PutHostCommandAcknowledgement", "codedeploy-commands-secure:PutHostCommandComplete" ],
注意点
上記はCodeDeployエージェントのバージョン1.1.2から対応しています。
- それより古いバージョンを利用している場合はCodeDeployエージェントを1.1.2以降に更新する必要があります。
- 参考:[ CodeDeploy エージェント - AWS CodeDeploy
エージェントのファイルを編集した後はサービス再起動をお忘れなく。。
でもやっぱりProxyを使いたい場合
VPCエンドポイント対応となった今ではあまりケースとしてはないかもしれませんが、codedeployagent.ymlにて":proxy_uri:"を指定すれば、使えるようになります。
例えば、以下のように記述します。
:proxy_uri: https://【Proxyサーバのホスト名】:【ポート番号】
以上。
【AWSの呼吸 壱ノ型】CodeDeployでハマった話
CodeDeployは標準でblue/greenデプロイに対応している便利サービスですよね。
ソースリポジトリからの取得・配置やロールバックなどの実行がマネージドで作りこみが不要なのがいいところです。
そんなCodeDeployを試していてハマってしまったので備忘として残します。
目次
やったこと
「AWSCodeDeployでblue/greenデプロイメントをやってみた | Tech ブログ | JIG-SAW OPS」を参考にCodeDeployのための準備をしました。
上記のサイトはblue/greenですが、今回はin-placeを試してみました。
一通り設定を終えて、マネコンからデプロイを実行してみるも失敗。。
失敗の詳細
事象
in-placeデプロイが失敗する。
デプロイの全てのステップがスキップされて何も処理されていない状態。
調査
「codedeploy-agent.log」に以下のエラーが出力されていた。
(/var/log/aws/codedeploy-agent/配下にCodeDeployエージェントが出力する実行ログです。)
2019-12-28 11:28:37 ERROR [codedeploy-agent(5462)]: InstanceAgent::Plugins::CodeDeployPlugin::CodeDeployControl: Error during certificate verification on codedeploy endpoint https://codedeploy-commands.ap-northeast-1.amazonaws.com
原因・対策
凡ミス・・・
CodeDeployのエンドポイントにNWアクセスできていないためでした。
今回のEC2インスタンスはプライベートセグメントに作成しており、所属しているサブネットにNATゲートウェイが設定されていませんでした。
EC2インスタンスをNATゲートウェイのあるサブネットに作り直し、NW的に疎通できる状態にしたところ、無事にデプロイが成功しました。
本エラーが出た時に疑った方がよい点
2021/1/12 追記: 2020年8月にVPCエンドポイントに対応しました! AWS CodeDeploy が VPC エンドポイントへのデプロイのサポートを開始
IAMロールが正しく設定されているか
「AWSCodeDeployでblue/greenデプロイメントをやってみた | Tech ブログ | JIG-SAW OPS」のようにEC2側とCodeDeploy側のそれぞれで適切なIAMロールが設定されていればOKCodeDeployエージェントが起動しているか
以下のように"running"と出ればOK
# service codedepoloy-agent status The AWS CodeDeploy agent is running as PID 2724
以上。
GitLabへのSSH接続でハマった話
新年あけましておめでとうございます。
IaCまわりの記事を読み漁っていたところコードが書きたくなり、GitLabを開設してみたものの上手くSSH接続ができなかったので、解決方法をまとめます。
SSH接続するための設定手順は検索すればたくさん出てくるので詳細は割愛します。
目次
やったこと
- GitLabにアカウントとProjectを作成
- クライアント端末側(Windows10)にGitBashをインストール
- GitBashにてsshキーペアを作成し、GitLabのSSH Keysに公開鍵を登録
「GitLabにSSHで接続するまでの手順 - Qiita」の手順を参考にさせていただきました。
が、しかし上手く接続できない
事象
一通り設定し終えてgit cloneしたところ、以下のエラーが発生してクローンできない。
$ git clone git@gitlab.com:hoge/my-project.git Cloning into 'my-project'... The authenticity of host 'gitlab.com (35.231.145.151)' can't be established. ECDSA key fingerprint is SHA256:HbW3g8zUjNSksFcqTiUWPWa2Bq1x9xdGMrluXFzSnUw. Are you sure you want to continue connecting (yes/no/[fingerprint])? yes Warning: Permanently added 'gitlab.com,35.231.145.151' (ECDSA) to the list of known hosts. git@gitlab.com: Permission denied (publickey). fatal: Could not read from remote repository. Please make sure you have the correct access rights and the repository exists.
SSHテストも同様にエラーが発生。
「Permission denied (publickey)」で接続できてないようです。
$ ssh -T git@gitlab.com git@gitlab.com: Permission denied (publickey).
試したこと
configを見直す
~/.ssh/configの記述内容を見直しました。
特に問題なしでした。
Host gitlab # sshで指定する任意の接続名
HostName gitlab.com # 接続先のホスト名またはIPアドレス
IdentityFile ~/.ssh/rsa_gitlab # 秘密鍵のパス
User git # 接続ユーザ(リモートURLアクセス時はgitで決め打ち)
GitLabのSSH Keysを見直す
作成した公開鍵がGitLab側で正しく登録されているか管理画面にて見直しました。
特に問題なしでした。
メールアドレスを指定してSSHキーペアを作り直す
「Git - GitLabにssh接続しようとすると「Permission denied (publickey).」|teratail」を参考にアカウント開設時に登録したメールアドレスを指定してSSHキーペアを作り直し、GitLabに再登録してみました。
コマンドは以下の通り、"-C"オプションをつけてssh-keygenを実行します。
実施後も特に事象は解消されず、接続できないままでした。
$ ssh-keygen -t rsa -b 4096 -f ~/.ssh/rsa_gitlab -C "GitLabの登録メールアドレス(ex: hoge@gmail.com)"
ssh-agentに秘密鍵を登録する
私の場合はこれで接続成功しました。
「【GitLab】SSH接続をテストする - Qiita」を参考にssh-agentを起動し、作成した秘密鍵を登録する方法です。
以下、手順を説明します。
$ ssh-add -l Could not open a connection to your authentication agent.
- ssh-agentを起動する
$ eval `ssh-agent` Agent pid 777
$ ssh-add -l The agent has no identities.
$ ssh-add ~/.ssh/rsa_gitlab Identity added: /c/Users/hoge/.ssh/rsa_gitlab (hoge@gmail.com)
- SSH接続テストを実行する
- 以下のように「Welcome to GitLab」と出れば、無事に接続成功です!
- 私の場合はこれでgit cloneも成功するようになりました。
$ ssh -T git@gitlab Welcome to GitLab, @hoge!
コメント
以前、別の端末でGitBashでSSH接続の設定を行った際はssh-agentの設定なんてした覚えがないのですが・・
何となくですがデフォルト名でキーペアを作らなかったせいなのでしょうか?
とにかく接続には成功したので、そこはあまり深堀りしないことにします。
以上。
CSPO研修を受けた件
先月、CSPO (Certified Scrum Product Owner)研修を受けてきたので、その時のメモを書き残します。 ※個人的に気になったキーワードについて、ただただメモしておくだけなので、取り留めはありません。
目次
CSPO研修とは?
- CSPOとは"Certified Scrum Product Owner"の略で認定スクラムプロダクトオーナーという意味です。
- 認定スクラムトレーナー(CST)によって開催される Scrum Alliance 認定のCSPO研修を受けることで認定されます。
- 引用元: CSPO研修(認定スクラムプロダクトオーナー研修)で学んだ「ROIを考え抜く姿勢」 - もくもくプロダクトマネジメント( @Nunerm )
講師の方
日本人とデンマーク人がタッグで研修を行ってくれました。
とても印象的なお二方でした。
サンダルとTシャツというラフなスタイルで、質問するとチョコレートを投げてくれたり。。笑
メモ
プロダクトバックログリファイメントミーティング
価値駆動
- インクリメンタル開発で少しずつつくる
- 例えば、UI~DBスキーマを各層でサイロ的にしっかりとつくるのではなく、横串で必要最低限を少しずつつくる
スプリント期間の考え方
- 日本は1週間がある
- 日本以外はだいたい2週間
- 1時間という考えの人もいる
プロダクトバックログ Ready
- Top3のスプリントがReadyならReady Ready
- 参考: ジェフ・サザーランド "Ready-Ready"
単体テスト
- 単体テストはやめよう
- UIテスト(エクスプロイトテスト)に時間を割くべき
完成の定義
- リファクタリングも入るか? ⇒ 入る。これがないと出荷できない
障害リスト
- 100個くらい書きだしてもよい
テストの網羅性
- TDD will kill you
- 要件を知らなくてもUTはできてしまう
- POが出すテストケースがDEVが行うテストケース
- テストカバレッジが正というのはウォーターフォールの概念
- 優先すべきはプロダクトの要求と完了条件
- 大事なのは今起きているバグを把握し、どういうプロセスでバグが再発しないようにするか!
- 非企能もPBIとして積まれたものをこなす
- PBIにのってこなければ、いつまでも対応されない
アジャイルへの投資
POチーム
- プロダクトを説明するために何が必要かを考える
開発チーム
- 1番大事なのは学ぶことができる人
- 研修でチームが育ち、プロダクトの価値に繋がるとしたら、それはバックログに入れるべき
スクラムマスター
- スクラムマスターはフルタイムで働くべき
- DEVとの兼任はNG
SAFe is bullshit
Scrum Scaleが良くない理由
- 個人と個人のやり取りホップ数が(大)
- ハブとなるマネージャが入れ歯成り立つが結果、それは非スクラム化する
Value (価値)の定量評価
タスクボード
- スプリント内でチームで選択したPBIを任意の順序でデリバリーできる
- スフォーミング「1つのPBIに群がって集中的に片付けること」を推奨
- 手づまったり、1人作業になっていたら、SCMがもっと上手いやり方がないか聞く
- ほとんどWIPで止まっている状態はよくない
レスポンシブデリバリー
- 実利用環境のバグは前スプリントが完了していないことを意味する
デイリースクラムの目的
- スプリントゴールの確認とリプラン
- 残りの期間をどう使うか確認
スプリントゴール
- DEVが自分たちで定めるのが望ましい
プロダクトバックログ
- 必ずしもユーザーストーリーでなくてもい
- ただ機能を書くだけでもよい
PBIの見積もり
- 作業量はチームの言い値 ⇒ チームごとに比較できるものではない
ユーザーストーリー
- 元々Featureと言われていた (本来は手書きのもの)
- POが要件を明確化していくための対話ツール