【AWSの呼吸 肆ノ型】Amazon Forecastで 新型コロナウイルスの感染者数を予測してみる
今回はAmazon Forecastを用いて、新型コロナウイルス感染症(COVID-19)の陽性者数を予測してみたいと思います。
※あくまでAWSの機械学習サービスの勉強の一環ですので、科学的な根拠に基づいて何か提唱するような記事ではありません。
目次
「Amazon Forecast」とは?
時系列データを基に機械学習で将来の数値の予測ができるサービスです。
例えば、EC2インスタンスのキャパシティや電力の使用量の予測が可能です。
予測結果
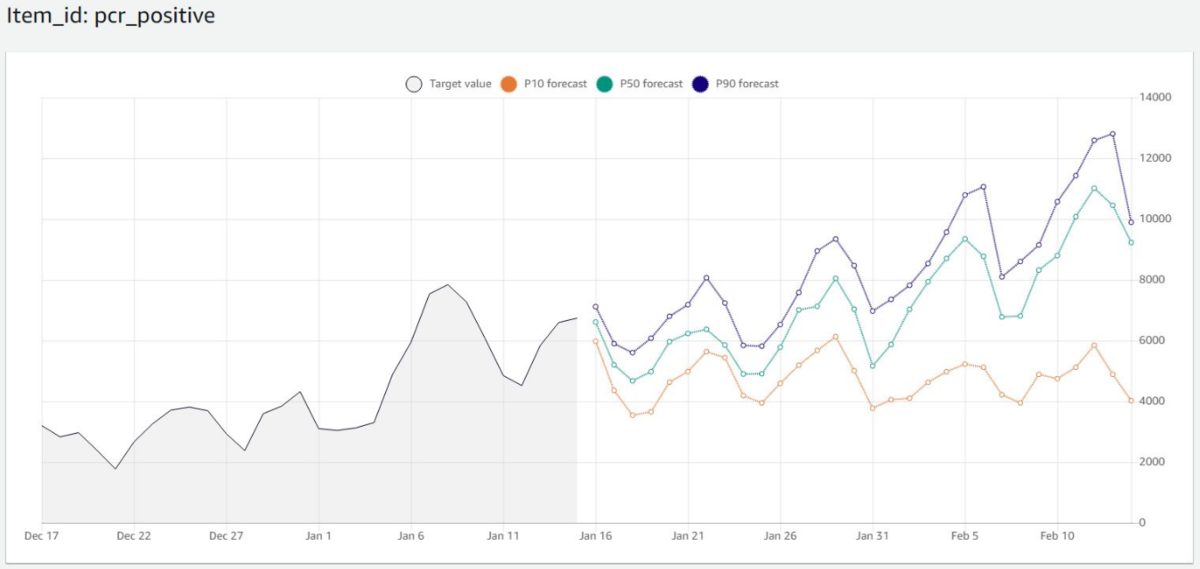
先に結果からお見せしてしまうと、こんな感じになりました。
来月には全国の陽性者数が1万人を超えるという予測です。

- P10:10パーセンタイル (下振れ値)
- P50:50パーセンタイル (中央値)
- P90:90パーセンタイル (上振れ値)
利用したデータ
- 厚生労働省が一般公開している日本国内の陽性者数のデータを利用します。
- 時系列のCSVデータです
- こちらからダウンロード可能です:オープンデータ|厚生労働省
- 今回のCSVデータの内容は以下の通りです
- 期間:2020/1/16~2021/15
- レコード数:366
- レコード内容: 日次の陽性者数
抜粋するとこんな感じのシンプルな時系列データです。
日付,PCR 検査陽性者数(単日) 2021/1/12,4521 2021/1/13,5841 2021/1/14,6598 2021/1/15,6741
Forecastで予測する期間
30日間 (2021/1/16~2021/2/14)
Forecastでの予測の流れ
ざっくりとデータ投入⇒学習⇒予測という流れです。
以降はこの流れにそって手順を説明していきます。
データ投入
Forecast用のデータ準備
データ加工
Forecastにデータを投入するためには事前にForecastで指定した形式にデータを加工しておく必要があります。 今回のケースでは以下の属性を含むデータとしました。
- item_id:予測対象の識別子 (string)
- timestamp:タイムスタンプ (yyyy-MM-dd形式)
- target_value:予測対象の数値 (float)
先述したCSVデータでは形式が合わないので、以下のように加工しています。(抜粋)
item_id,timestamp,target_value pcr_positive,2021-01-12,4521 pcr_positive,2021-01-13,5841 pcr_positive,2021-01-14,6598 pcr_positive,2021-01-15,6741
S3アップロード
後述の"dataset"からデータを参照できるように加工したデータを任意のS3バケットにアップロードしておきます。
datasetgroup作成
ここからいよいよForecastの設定に入ります。
AWSマネジメントコンソールから[Amazon Forecast] > [Create dataset group]を選択し、時系列データのグループを定義します。
下記の画面のように入力し、[Next]を押します。

- ①dataset group name:時系列データのグループ名
- 任意の名前でOKですが、ハイフンを使えないのでアンスコで区切る必要があります
- ②Forecasting domain:EC2キャパシティなどForecastのプリセットの時系列データのタイプ
- 今回は該当のタイプがないため、"Custom"を指定しました
dataset作成
次に時系列データの項目を定義します。
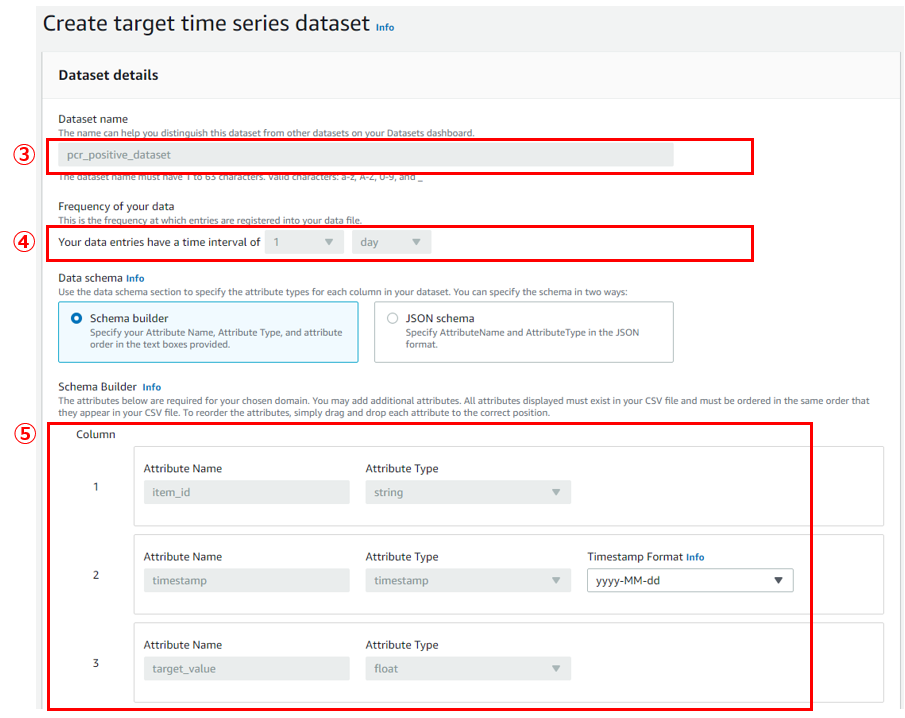
- ③Dataset name:時系列データ名
- 任意の名前でOKですが、ハイフンを使えないのでアンスコで区切る必要があります
- ④Frequency of your data:時系列データの間隔
- デフォルトで1day=日次になっているはずです
- 今回は日次データを扱うので、そのままでいきます
- ⑤Column:時系列データの列項目
- Forecasting domainがCustomの場合はitem_id,timestamp,target_valueが自動で定義されています
- TimestampFormatは元データに時間がないため、yyyy-MM-dd形式に変更しました
次に下記のようにインポートする時系列データを選択し、[Start Import]を押します。 今回のデータでは完了までに2~3分ほどかかりました。
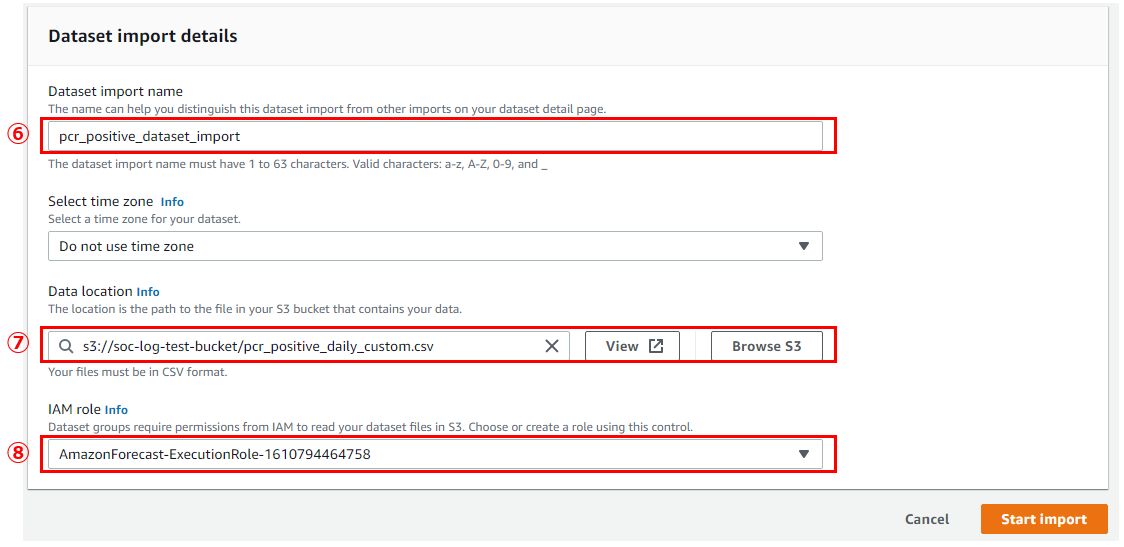
- ⑥Dataset import name:インポートする時系列データ名
- 任意の名前でOKですが、ハイフンを使えないのでアンスコで区切る必要があります
- インポート済みの名前と重複する場合はエラーで怒られます
- インポートするCSV名に合わせて名前を変えていくと管理上よいかと思います
- ⑦Data location:インポートする時系列データのS3バケット上のパス
- 先ほどアップロードしたCSVファイルのパスを指定しました
- ⑧IAM role:Forecast用のIAMロール (S3アクセス用)
- 今回はお試しなので、自動生成のロールをそのまま使ってます
処理が完了したら下図の通りダッシュボード上のステータスが"Active"となります。
"Active"が確認できたら、"Predictor Training"の[Start]を押して次に進みましょう。
学習
predictor作成
先ほどインポートした過去の時系列データを基に予測の判断材料をつくります。
下図の通り、predictorの設定を行います。

- ⑨Predictor name:作成するPredictor名
- 任意の名前でOKですが、ハイフンを使えないのでアンスコで区切る必要があります
- ⑩Forecast horizon:予測したい期間
- 今回は予測したい期間を30日間としたいので、30を指定しました
以降、predictorの学習方法について詳細を設定していくのですが、今回はお試しなので全てデフォルト設定で次に進みます。

- ⑪Forecast horizon:学習アルゴリズム
- カスタマイズしたい人はManualで指定できるようですが、今回はお試しなのでお任せのAutomaticにしました。
他にも色々とオプションはありますが、すっ飛ばして、最後に[train predictor]を押します。
レコード数がそれほど多くないのですぐ終わるかなと思っていたのですが、完了するまでにそれなりに時間かかります。
夜に放置して次の日の朝に終わっていることを確認したので、正確な時間は分からないですが、今回のケースでは少なくとも1時間以上はかかってます。
処理が完了したら下図の通りダッシュボード上のステータスが"Active"となります。
"Active"が確認できたら、"Forecast generation"の[Start]を押して次に進みましょう。
予測
forecast作成
予測の定義を作ります。
下図のforecastの詳細を指定して、[Create new forecast]を押します。
今回のケースでは完了までに30分ほどかかりました。
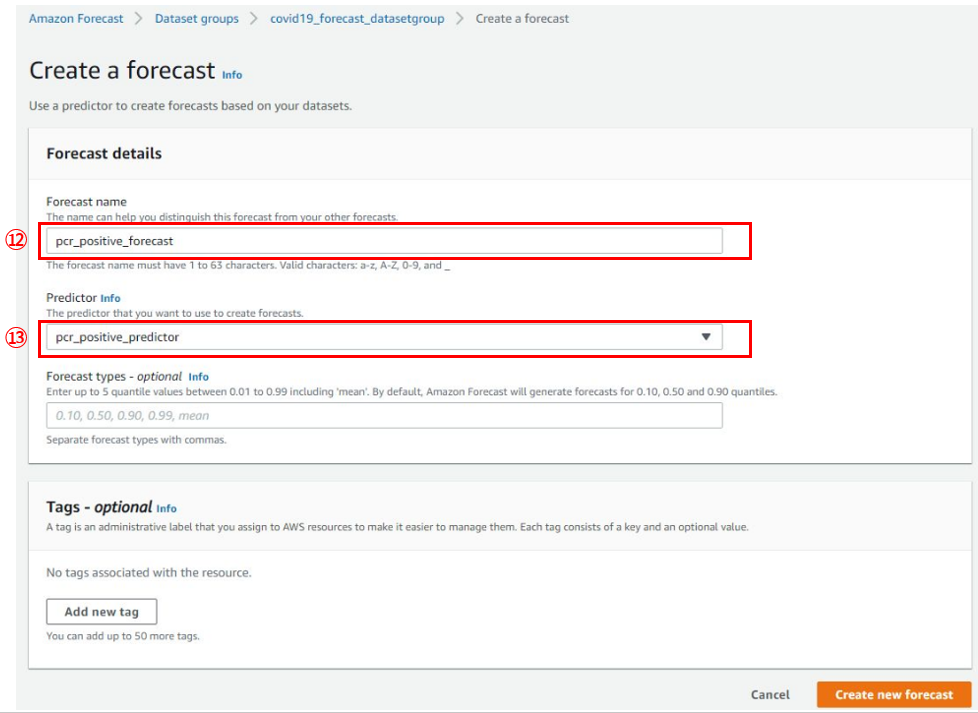
- ⑫Forecast name:作成するForecast名
- 任意の名前でOKですが、ハイフンを使えないのでアンスコで区切る必要があります
- ⑬Predictor:利用するpredictor
- 先ほど作成したpredictorを指定しました
処理が完了したら下図の通りダッシュボード上に[Lookup forecast]のボタンが現れるので、押して次に進みましょう。

予測結果の参照
ここまできたらあとは結果をグラフで表示させるだけです。
下図のように見たい項目と期間を選んで、[Get Forecast]を押します。
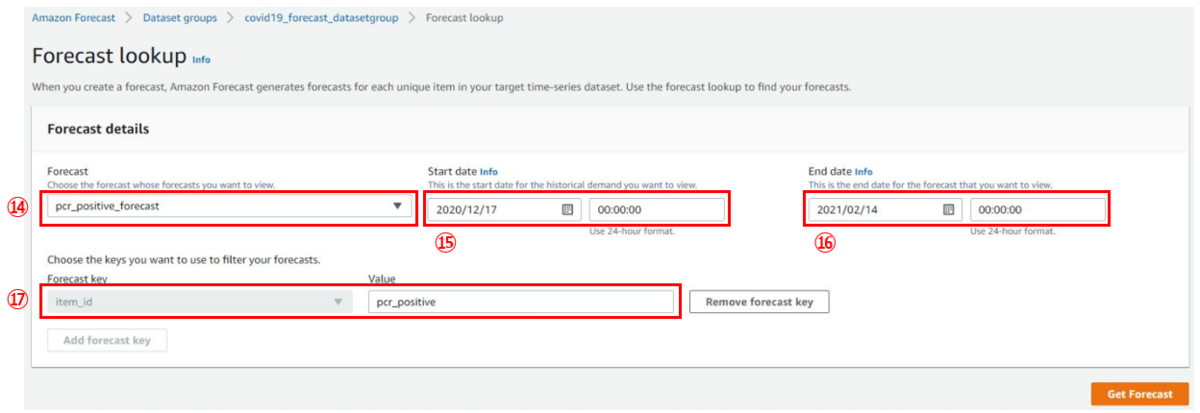
- ⑭Forecast:利用するForecast名
- 先ほど作成したものを指定します
- ⑮Start date:表示させたい開始日時
- 今回はForecast horizonで30を指定している関係で投入したデータの30日前まで指定可能になっていると思われます
- ⑯End date:表示させたい終了日時
- 今回はForecast horizonで30を指定している関係で投入したデータの30日後まで指定可能になっていると思われます
- ⑰Value:表示させたい項目
- datasetで投入したデータのitem_idの値="pcr_positive"を指定しました
すると冒頭でお見せした結果が取得できます!
参考にしたページ
以上。