【忘却のJava#7】JSUG勉強会#4の参加レポート
勉強会に参加して、良い刺激を受けたので書き残したいと思います。
個人用の備忘で文章が拙劣なのは、あしからずでございます。
これまでインフラまわりの勉強会には参加してきましたが、アプリよりは初めてだったので少し緊張しました。笑
登壇者の方々は発表は苦手と言いつつ、一生懸命伝えようとしてくれた所が好印象でした。
目次
開催概要
テーマ
JSUG勉強会 2019その4 初心者による初心者のSpring入門
日時
2019/04/25(金) 19:00~21:00
場所
六本木ヒルズ森タワー20F Pivotal Japan
セッション
4つのセッションが用意されていました。
- JSUGの正しい参加方法 (柴田 洋平さん - JSUGスタッフ)
- Spring Coreの解説 (田村 英雄さん - Guildhub)
- Spring 歴約1年初心者の Test 奮闘記 (内藤千静さん - タグバンガーズ)
- Spring Boot × Vue.jsでSPAを作る (宮坂 豪さん - アクロクエストテクノロジー)
以下はその所感とメモです。
JSUGの正しい参加方法
概要
JSUGの成り立ちや参加スタイルについて教えてくださいました。
登壇者を絶賛募集中とのことです。
所感
おそらくSpring界隈でテックメインでやっていくことはないので登壇という形でお役立てはできないかもしれませんが、これからも参加していきたいと思いました。
Spring Coreの解説
概要
DIコンテナがどのように機能しているのか、自身が理解するまでの流れをFactoryやBean定義ファイルをもとに説明してくださいました。
所感
技術者として簡単な技術を上手く使えるということも大事ですが、原則原理や成り立ちを知っているということもまた大事だと個人的には思うので、そのような説明が聞けたのは良かったです。
でも実は私はSpringBootのHelloWorldレベルしかやってなくてスプリングのスの字も分かってないので、肝心のDIコンテナやらFactoryやらBeanやらの中身はポカーンでした。
なので、ここに備忘として書いておいて、次回までには抑えておければと思ってます。
メモ
- 以前はSpring(DIコンテナ)がどうやってServiceとRepositoryをインスタンス化しているか分からなかった。。
- Controller -> Service -> Repository -> DBのような関係性でServiceがnewされる度にRepositoryが勝手に作られる蜜結合の状態を避けたい
- ⇒インタフェースとFactoryを利用すればよい
- Factoryクラスを毎回作るのは大変⇒設定ファイルからインスタンス化対象を読み取り、インスタンス化したい
- クラスの置き換えには実装の変更が必要⇒設定ファイルから依存関係を読み取り、インスタンス化したクラスに注入したい
- これらはReflectionを使えば実現できる!
- Reflectionはクラス名(文字列)から、インスタンスの生成ができる
- setter injectionとかauto wiredとか
- これらを理解する前にBean定義ファイルを勉強せよ
- Bean定義ファイルを使っての開発はSpringの基礎なので、しっかり勉強しておくことがオススメ!
- 金融案件なんかではまだ使っているところもある
Spring 歴約1年初心者の Test 奮闘記
概要
Springを使った開発におけるTestの自動化方法について説明してくださいました。
所感
Springもよく知らない、Testもよく知らない状態から実際に仕事で使えるところまで成長されたところが素晴らしいと思いました。
SpringやTestをあまり知らない人向けに説明してくれていたので分かりやすかったです。
メモ
- 依存している未完成のクラス多くてmockないとTestきついとき
- Mockitoを使ってMockitoJUnitRunner.classを差し込めばいける
- @Mock / @InjectMockを使ってTest対象のクラスをUnit Testする
- SpringRunnerとは?
- Bean同士の連携テストを行いたい、テスト上でDIコンテナを活用したいときに使用する機能
- @RunWith(SpringRunner.class)をおまじないとして書く
- @WebMvcTestで仮想Web層をたててレスポンスステータスのチェックTestとかできる
- MockMvcResultMatchers.jsonPathでjsonのエラーメッセージのチェックも可能
- データベースへのIntegration Test
- DB接続は@DataJpaTestでTest
- DBのTestにはデータがいるのでH2という内臓DBでデータをつくる
- SpringRunnerを使用することでテストの幅が広がる (Web MVCいける)
- SpringでのUnitTestは書きやすい(一年初心者の私でも書けた!)
Spring Boot × Vue.jsでSPAを作る
概要
まさにタイトルの通りですが、ご自身が作成されたSpring Boot + Vue.jsのアプリ構成や構築するまでの流れを解説していただきました。
所感
登壇者の方も言っていましたが、平成最後に聴いたプレゼンとなりました。
そう思うと感慨深いです。
仕事的にタイムリーな内容だったので楽しく聴かせていただきました。
いまどきはVueでSPAつくって処理はフロントエンドに寄せるんだよ、なんて話をどこかで聞いていはいましたが、まさにそのような構成になっていてだいぶイメージが湧きました。
メモ
- SPAとは?
- 構成は?
- クライアント <-> Vue.js <-> Spring Boot <-> Mybatis <-> MySQL
- やったことの流れ
- (1)Spring Bootプロジェクトの雛形作成
- (2)Spring Bootに書くAPIの機能を実装
- (3)Spring Security認証周りを整備
- (4)Vue.jsで画面周りを実装
- (5)Vue.jsのビルド媒体をSpring Boot内に配置
- (6)Spring Bootだけでアプリ起動可能に
- (1)Spring Bootプロジェクトの雛形作成
- Spring Initializrで雛形を作成
- Webページからさくっと雛形を作れる
- (2)Spring Bootに各APIの機能を実装
- (3)Spring Security認証周りを整備
- (4)Vue.jsで画面周りを実装
- (5)Vue.jsのビルド媒体をSpring Boot内に配置
- (6)Spring Bootだけでアプリ起動可能に
- あとは java -jar xxx.jarで起動するだけ
- Spring Securityとして静的ファイルへのアクセス許可が必要
- はまりどころ
- ユーザ情報はクライアントサイドでどう管理する?
- stateで一元的に管理する
- セッション管理はVue.jsの設定等でも実現できるのでは?
- サーバ再起動時などサーバとクライアント側で整合性が取れなくなる場合もあると考え、同期がとれる方式にした
資料
まだ公開されていないようなので追って更新します。
以上。
【忘却のJava#6】IntelliJ IDEA + Spring BootでHello Worldしてみる
Webアプリをつくる必要が出てきたのでSpring Bootを試してみました。
目次
やりたいこと
Spring Boot環境を構築し、WebブラウザからHello Worldを表示する
環境情報
流れ
IntelliJ IDEAのインストール
- IntelliJ IDEAの公式サイトからexeファイルをダウンロードする
- Community版の「Windows, JBR 11 (.exe)を選択
- exeを実行し、インストールを開始する
- 全部デフォルト設定で[next]で進めていき、[install]ボタンを押下する
- 10分くらいかかる
- プログラムを開き、以下の通り進める
- Import IntelliJ IDEA Settings From..というページが開くので、[Do not import settings]を選択する
- Privacy Policyに同意する
- Data Sharingで[Don't send]を選択する
- UI themeで好きなテーマを選択する
- [Skip Remaining and Set Defaults]を選択すると以下のようなメニュー画面が開く
OpenJDKのダウンロードとPath設定
- OpenJDKのアーカイブ からzipファイルをダウンロードする
- 今回は「11.0.2 Windows 64-bit」を選択する
- ダウンロードができたらzipを解凍し、jdk-11.0.2フォルダを適当な場所に配置する
- 今回は「C:\Program Files\Java\jdk-11.0.2」というかたちで配置する
- システムの詳細設定から環境変数のPathを設定する
Spring Initializrによる雛形プロジェクトのダウンロード
- Spring InitializrのWebページにアクセスする
- 以下のように選択する
- Project: Gradle Project (変更)
- Language: Java (デフォルト)
- Spring Boot: 2.1.4 (デフォルト)
- Project Metadata:
- Group: com.example (デフォルト)
- Artifact: demo (デフォルト)
- Name: demo (デフォルト)
- Description: Demo project for Spring Boot (デフォルト)
- Package Name: com.example.demo (デフォルト)
- Packaging: Jar (デフォルト)
- Java Version: 11 (デフォルト
- Dependencies:DevTools / Lombok / Web / Thymeleaf / JDBC
(後でbuild.gradleにて編集できるので、ひとまず必要になりそうなものを選ぶ)
画面上は下図のようになる。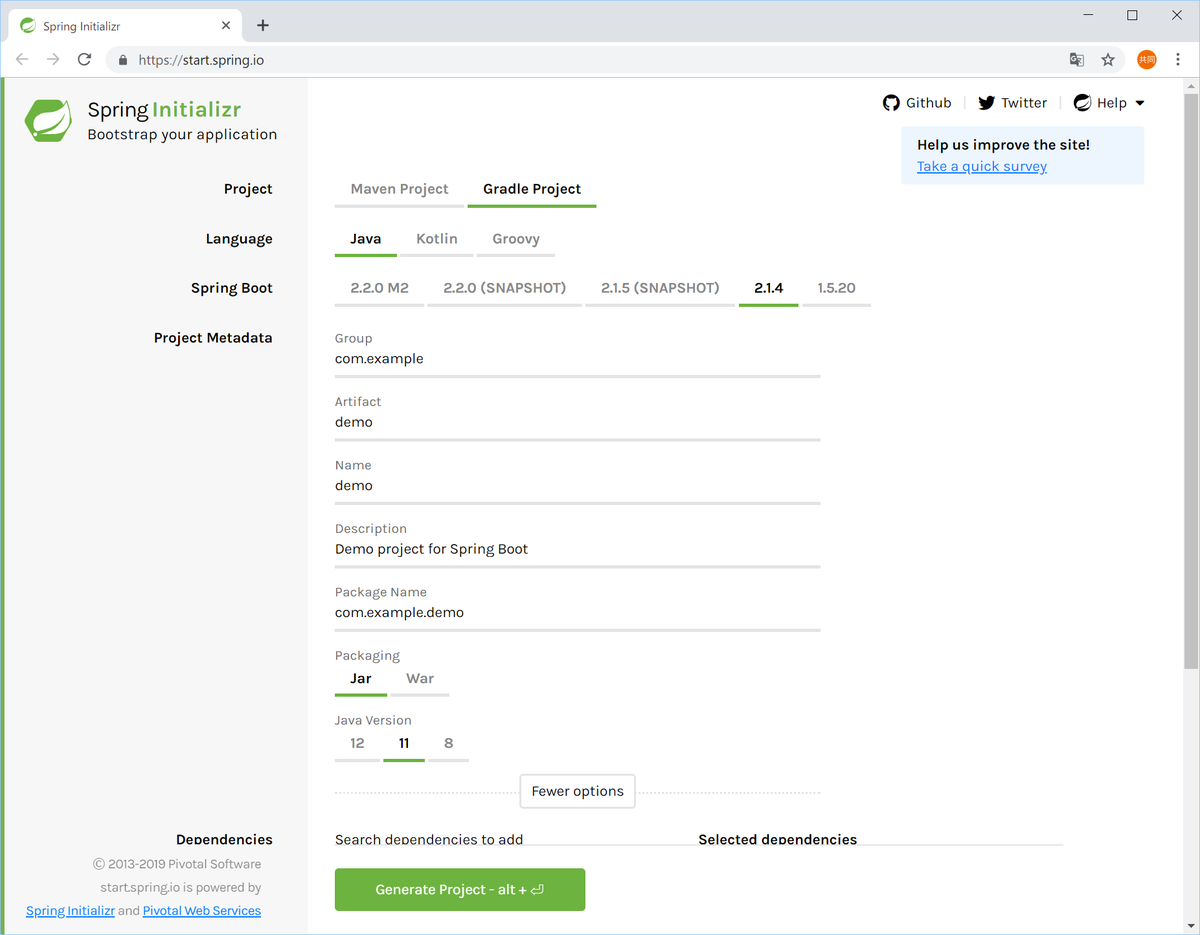
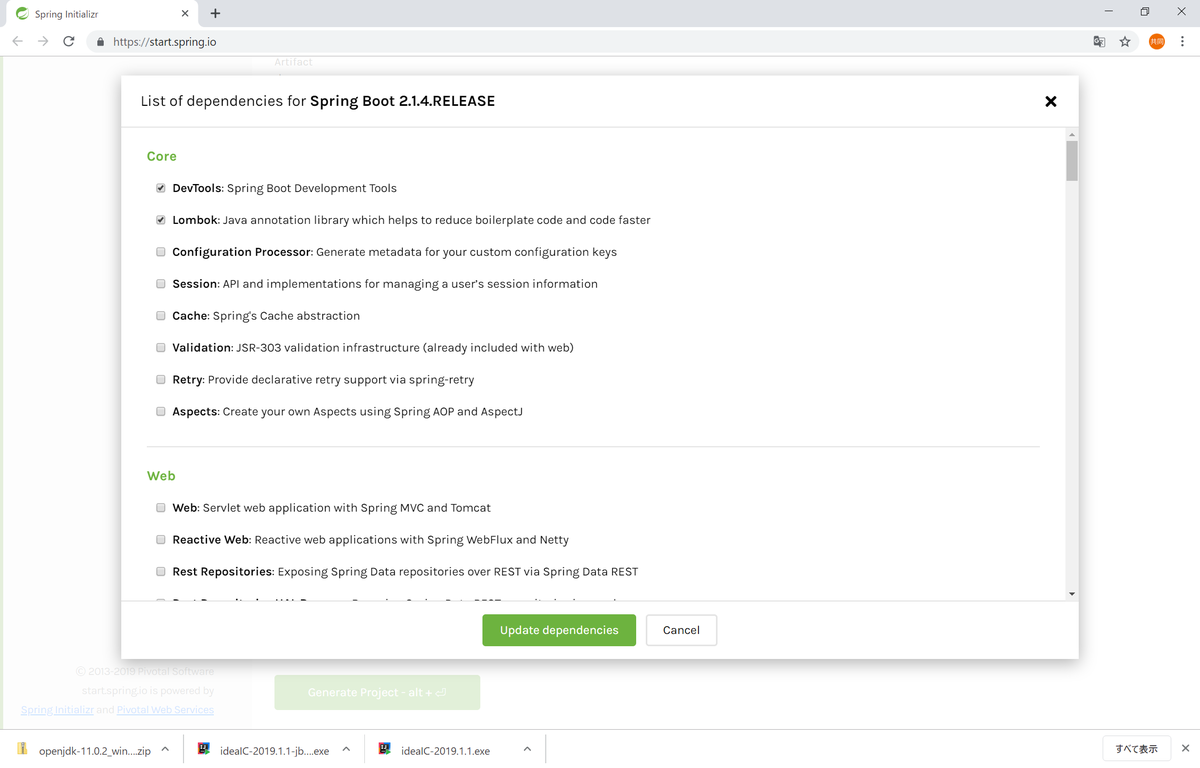
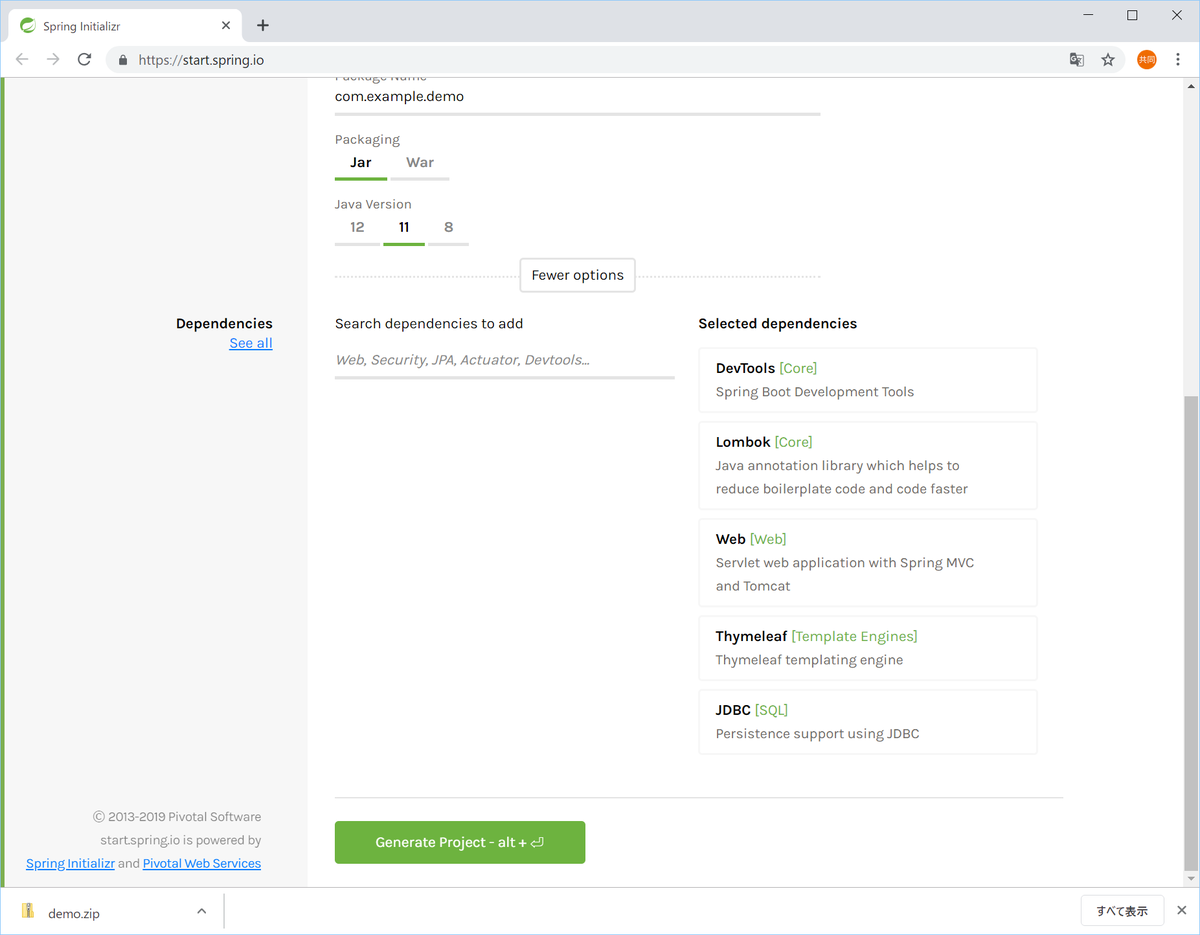
- [Generate Project]を押下し、zipファイルをダウンロードする
- zipファイルを解凍し、ワークスペースに配置する
- 今回は「C:\work\demo」に配置する
雛形プロジェクトを開き、Gradleビルドの実行
- [Welcome to IntelliJ IDEA]メニューの[Open]を押下する
- 「C:\work\demo」を選択し、[OK]を押下する
- [Import Project from Gradle]の画面が表示されたら、[Gradle JVM]にて先ほど配置したJDKのパス「C:\Program Files\Java\jdk-11.0.2」を指定して[OK]を押下する

- [Tips of the day]が表示されるので[Close]を押下する
- アノテーション機能を有効化する
- Crtl+Alt+SでSettings画面を開く
- 下図の通り「Enable annotation processing」のチェックを入れ、[OK]を押下する
- 左ペインの[build.gradle]をダブルクリックすると新しいバージョンのGradleを使用してビルドすることを推奨されるので、[OK, apply suggestion!]を押下する
- 10分くらいかかる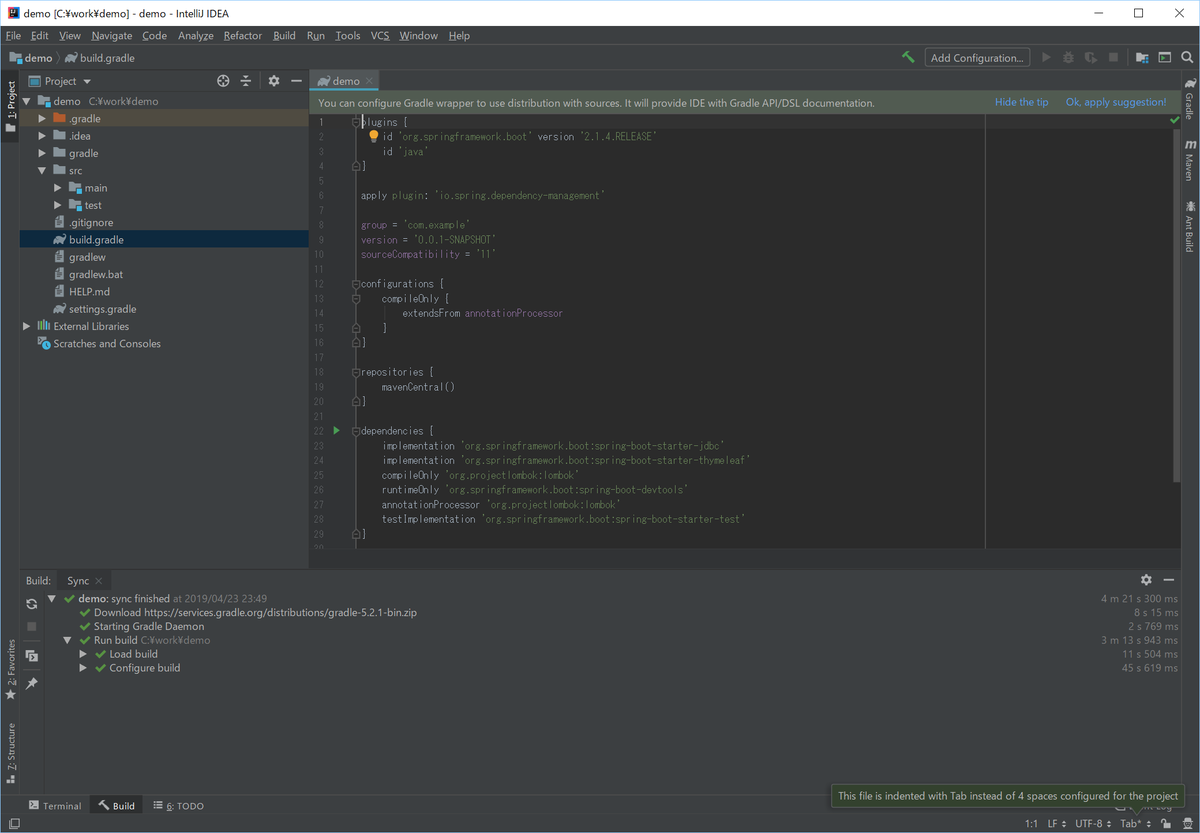
コントローラとHTMLの追加
- 「com.example.demo」配下に「HelloWorld」パッケージを追加し、その配下に「HelloWorldController.java」を作成する
- 「resouces/templates」配下に「HelloWorld.html」を作成する
- 「HelloWorldController.java」と「HelloWorld.html」はそれぞれ以下のように記述する
HelloWorldController.java
package com.example.demo.HelloWorld; import org.springframework.stereotype.Controller; import org.springframework.web.bind.annotation.GetMapping; @Controller public class HelloWorldController { @GetMapping("/helloworld") public String HelloWorld() { return "HelloWorld"; } }
HelloWorld.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Hello World</title> </head> <body> <h1>Hello World!</h1> </body> </html>
IntellJ IDEA上ではこのようになります。
アプリケーション実行
ここまで来たらあとは実行するだけです。
- Intellij IDEAにてDemoApplicationを選択し、[Run 'DemoApplication.main()']を押下する
- 以下の通り、[Started DemoApplication...]と表示されれば起動成功
こんな風にSpringの文字が出ます。
(これは少し崩れてますが・・)
. ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v2.1.4.RELEASE) 2019-04-24 01:17:39.645 INFO 8464 --- [ restartedMain] com.example.demo.DemoApplication : Starting DemoApplication on DESKTOP-ROVHDC9 with PID 8464 (C:\work\demo\out\production\classes started by wingg in C:\work\demo) 2019-04-24 01:17:39.645 INFO 8464 --- [ restartedMain] com.example.demo.DemoApplication : No active profile set, falling back to default profiles: default 2019-04-24 01:17:39.724 INFO 8464 --- [ restartedMain] .e.DevToolsPropertyDefaultsPostProcessor : Devtools property defaults active! Set 'spring.devtools.add-properties' to 'false' to disable 2019-04-24 01:17:39.724 INFO 8464 --- [ restartedMain] .e.DevToolsPropertyDefaultsPostProcessor : For additional web related logging consider setting the 'logging.level.web' property to 'DEBUG' 2019-04-24 01:17:41.626 INFO 8464 --- [ restartedMain] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http) 2019-04-24 01:17:41.657 INFO 8464 --- [ restartedMain] o.apache.catalina.core.StandardService : Starting service [Tomcat] 2019-04-24 01:17:41.657 INFO 8464 --- [ restartedMain] org.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/9.0.17] 2019-04-24 01:17:41.801 INFO 8464 --- [ restartedMain] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2019-04-24 01:17:41.801 INFO 8464 --- [ restartedMain] o.s.web.context.ContextLoader : Root WebApplicationContext: initialization completed in 2077 ms 2019-04-24 01:17:42.082 INFO 8464 --- [ restartedMain] o.s.s.concurrent.ThreadPoolTaskExecutor : Initializing ExecutorService 'applicationTaskExecutor' 2019-04-24 01:17:42.379 INFO 8464 --- [ restartedMain] o.s.b.d.a.OptionalLiveReloadServer : LiveReload server is running on port 35729 2019-04-24 01:17:42.457 INFO 8464 --- [ restartedMain] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path '' 2019-04-24 01:17:42.457 INFO 8464 --- [ restartedMain] com.example.demo.DemoApplication : Started DemoApplication in 3.311 seconds (JVM running for 3.917)
ブラウザでの動作確認
- Chromeを起動する
- 「http://localhost:8080/helloworld」にアクセスする
- 以下の通り「Hello World!」が表示される

実はこの前に1度エラーで実行に失敗してます
エラー事象
DemoApplicationを実行後、以下のエラーが発生し、起動に失敗しました。
2019-04-24 01:03:24.778 ERROR 8712 --- [ restartedMain] o.s.b.d.LoggingFailureAnalysisReporter : *************************** APPLICATION FAILED TO START *************************** Description: Failed to configure a DataSource: 'url' attribute is not specified and no embedded datasource could be configured. Reason: Failed to determine a suitable driver class Action: Consider the following: If you want an embedded database (H2, HSQL or Derby), please put it on the classpath. If you have database settings to be loaded from a particular profile you may need to activate it (no profiles are currently active). Class transformation time: 0.049822762s for 5710 classes or 8.725527495621715E-6s per class Process finished with exit code 0
エラー内容の調査
エラー文言でググると以下の記事がヒット。
データソースの自動設定を無効化すると解消されるという内容です。
StackOverFlow
「Failed to configure a DataSource: 'url' attribute is not specified and no embedded datasource could be configured. SPRING」
原因
不明です。
というか今回やりたいことに対して本質的な問題ではないので、詳しくは調べていません。
何となくですが、Spring Bootとして基本的な挙動なのか、JDBCをDependenciesに追加しているせいなのかで、データストアに関する設定が事前にできていないとエラーになると思われます。
対策
上記の記事に書いてあるとおり以下のコードをDemoApplication.javaに追加しました。
追加後、改めて実行するとエラーが解消し、無事に起動成功しました。
@EnableAutoConfiguration(exclude={DataSourceAutoConfiguration.class})」
【とはメモ#3】「Spring Boot」とは?
Spring Bootを使ってWebアプリを作ることになりそうなので、調べておくことにしました。
「Spring Boot」とは?
- Javaを使ったWebアプリケーション開発を簡単にするためのフレームワーク
- アプリケーションをつくるために必要なライブラリ群をまとめたSpring Frameworkをコア技術としている
- Spring Frameworkベースのアプリケーションを素早く簡単に作成、実行、配布するためのサポート機能を提供する
具体的にどんなことができるのか?
- ライブラリ群とコードの雛形が用意されており、一からコーディングする必要がない
- アノテーション(注釈)を記述するだけでWebAPI等が実装でき、コード量を削減できる
- Spring Frameworkでは必須だったXMLファイルによる複雑な設定(DB接続情報など)が不要になった
- Tomcat、JettyなどWebコンテナをjarに内蔵することで、jar単体でWebアプリケーションが実行できる
まだ使ってないので、ピンと来ていないところもあります。
そもそも今回は書かなかったですが、Spring Frameworkの概念としてDIとかAOPとかBeanとか何じゃそれ状態なので勉強しないとですね。
実際使ってみたら、所感を書きたいと思います。
参考
以下のサイトを参考にさせていただきました。
多様化するJavaのフレームワーク問題を解決する、「Spring Boot」とは? (1/3):CodeZine(コードジン)
【Java】SpringBootとは?
以上。
【忘却のJava#5】組み合わせ最適化問題を解くプログラムをJavaで書く(2)
やること
以下の記事で紹介したCのプログラムをJavaに書き換えます。
wing-degital.hatenablog.com
目次
Javaへの書き換えのポイント
せっかくなのでCにはないJavaならではの方法をわざわざ使って実装しました。
classと二次元配列
どんなデータ構造?
classはオブジェクトの設計書のようなものでCの構造体のようにメンバー(変数や配列)を定義できます。
構造体と違うのはメンバーに加えてメソッド(関数)が定義できるところです。
用途は?
グラフを表現するために使いました。
頂点数と辺の集合をメンバーで持たせています。辺の集合は二次元配列で定義してます。
ArrayList
どんなデータ構造?
可変長の配列です。
配列への要素の追加、削除といった操作ができるメソッドがついていて便利です。
用途は?
辺集合とUnion-Findの部分集合を表現するために使いました。
正直、この手の組み合わせ最適化問題は固定長の集合で計算できるのでclassと配列でも表現できるのですが、無理やり使いました。
HashSet
どんなデータ構造?
要素の重複を許さない集合です。
内部的には配列とハッシュ値と線形リストの組み合わせで実現してるっぽいですね。
用途は?
Union-Findの集合の管理に使おうと思ったのですが、データ構造的に冗長過ぎるのでやめました。
配列だけで表現できます。
Javaのコード
実際に書き換えたのがこちらです。
Graph.java
public class Graph { int ord; int [][] adj; public Graph(int n){ this.ord = n; this.adj = new int[n][n]; } public void setGraph(int input[][]){ adj = input; } public void printGraph(){ for (int array[] : adj){ for (int val : array) { System.out.printf("%4d", val); } System.out.println(""); } } public int countTotalEdgeCost() { int sum = 0; for (int i = 0; i < this.ord; i++) { for (int j = i + 1; j < this.ord; j++) { sum += this.adj[i][j]; } } return sum; } }
EdgeList.java
import java.util.ArrayList; import java.util.Iterator; public class EdgeList { static ArrayList<Edge> edgeList = new ArrayList<Edge>(); public EdgeList(Graph g){ for (int i = 0; i < g.ord; i++) { for (int j = i + 1; j < g.ord; j++) { if(g.adj[i][j]> 0) { this.addEdgeList(g.adj[i][j], i, j); } } } } public void addEdgeList(int cost, int src, int dest) { Edge ed = new Edge(cost, src, dest); edgeList.add(ed); } public void printEdgeList() { for (Iterator<Edge>itr = edgeList.iterator(); itr.hasNext();) { Edge e = itr.next(); e.printEdge(); } } public void swapEdge(int i, int j) { Edge temp = new Edge(0, 0, 0); temp = edgeList.get(i); edgeList.set(i, edgeList.get(j)); edgeList.set(j, temp); } public void quickSortEdgeList(int low, int high) { int mid = (low + high) / 2; int i = low; int j = high; double pivot = edgeList.get(mid).cost; while (true) { while (edgeList.get(i).cost < pivot) { i++; } while (edgeList.get(j).cost > pivot) { j--; } if (i >= j) { break; } swapEdge(i++, j--); } if (low < i - 1 ) { quickSortEdgeList(low, i - 1); } if (j+1 < high ) { quickSortEdgeList(j + 1, high); } } class Edge { int cost; int src; int dest; public Edge(int cost, int src, int dest) { this.cost = cost; this.src = src; this.dest = dest; } public void printEdge() { System.out.printf("%d<->%d (cost:%d)%n", this.src, this.dest, this.cost); } } }
mst.java
import java.util.ArrayList; import java.util.Iterator; class Kruskal { public Graph execKruskal(Graph g, Graph tree) { EdgeList edl = new EdgeList(g); FlagmentList flml = new FlagmentList(g.ord); int edge_num = edl.edgeList.size(); int src = 0; int dest = 0; int cnt_edge = 0; edl.quickSortEdgeList(0, edge_num-1); for (int i = 0; i < edge_num; i++) { src = edl.edgeList.get(i).src; dest = edl.edgeList.get(i).dest; // find if cycle exist or not if (flml.findParent(src) != flml.findParent(dest)) { // add edge in MST tree.adj[src][dest] = g.adj[src][dest]; tree.adj[dest][src] = g.adj[dest][src]; // marge set flml.Union(flml.flmList.get(src).parent, flml.flmList.get(dest).parent); cnt_edge++; } if (cnt_edge == (g.ord -1)) { break; } } //edl.printEdgeList(); return tree; } class FlagmentList { ArrayList<Flagment> flmList = new ArrayList<Flagment>(); public FlagmentList(int ord) { for (int i = 0; i < ord; i++) { this.addFlagmentList(i, 0); } } public void addFlagmentList(int parent, int rank) { Flagment flm = new Flagment(parent, rank); flmList.add(flm); } int findParent(int x) { return flmList.get(x).parent; } void Union(int x, int y) { Flagment flmX = flmList.get(x); Flagment flmY = flmList.get(y); if (flmX.rank > flmY.rank){ flmY.setFlagment(flmX.parent, flmX.rank); } else { flmX.setFlagment(flmY.parent, flmY.rank); if (flmX.rank == flmY.rank) { flmX.addRank(); flmY.addRank(); } } } class Flagment { int parent; int rank; public Flagment(int parent, int rank){ this.parent = parent; this.rank = rank; } public void setFlagment(int parent, int rank){ this.parent = parent; this.rank = rank; } public void setFlagment(int parent, int rank){ this.parent = parent; this.rank = rank; } public void addRank(){ this.rank++; } } } } public class mst { public static void main(String[] args) { // create graph int maze[][] = { { 0, 7, 15, 0, 0, 0 }, { 7, 0, 12, 6, 0, 0 }, {15, 12, 0, 18, 17, 2 }, { 0, 6, 18, 0, 13, 0 }, { 0, 0, 17, 13, 0, 24 }, { 0, 0, 2, 0, 24, 0 } }; int n = maze.length; Graph g = new Graph(n); // graph Graph tree = new Graph(n); // graph int tc; // total cost // make graph g.setGraph(maze); // show test data System.out.println("Tree (result)"); g.printGraph(); // make MST by Kruskal Method Kruskal kruskal= new Kruskal(); tree = kruskal.execKruskal(g, tree); // show result System.out.println("Tree (result)"); tree.printGraph(); tc = tree.countTotalEdgeCost(); System.out.printf("total cost:%d\n", tc); } }
実行結果
前回と同じように最適解が得られました。
# java mst Graph (problem) 0 7 15 0 0 0 7 0 12 6 0 0 15 12 0 18 17 2 0 6 18 0 13 0 0 0 17 13 0 24 0 0 2 0 24 0 Tree (result) 0 7 0 0 0 0 7 0 12 6 0 0 0 12 0 0 0 2 0 6 0 0 13 0 0 0 0 13 0 0 0 0 2 0 0 0 total cost:40
【TECH:CAMP】現場フリーランスの生の声を聴いてきました
これからはデジタル領域にフォーカスして仕事をしていく予定なのですが、今後、IT人材不足が叫ばれる中でフリーランスの方と組んで仕事をする機会が増えるのではと思っています。
というか社内のリソースだけに閉じていてもビジネスがスケールできない時代がくると思ってます。
ということで、こちらにセミナーに行ってきました。
https://tech-camp.in/expert/lp/freelance_engineer_conferencetech-camp.in
以下はその際のメモです。
フリーランスになったきっかけ
・自由にマイペースで仕事したいから
・企業の枠ではなく、自分が何ができるかで評価されたいから
仕事
・契約にもよるがスケジューリングは基本的に自由
・常にリモートワークでできるところもあれば、週3のコアタイムはあるところもある
・未経験からコードを書いてお金をもらうには独学だけでは知れないレベルを掴む
現場のエンジニアに劣らないようにスキルを身に付ける
・人脈を広げるために色んなイベントにとにかく顔を出して、自分がやってること、やれることを話していた
・単価交渉には自分の実力を示す必要がある
最初はとにかく言い値でお試しでつかってもらった
・自分を売り込むためにどんな案件をこなして、どういう技術を使ったか記録で残しておく
・将来の不安はいつ仕事が切られるかわからないこと
・前回の仕事や紹介で仕事が巡ってくる
キャリア
・会社のステータスだけでは転職できない時代がくる
どんな物が作れるか、どんなことができるかが大切
・どんな方向に自分を育てていきたいかキャリアプランは自分で立てるしかない
・とにかく量をこなしていけば、未経験からでもなんとかなる
未経験者は1000~1500時間が必要というデータがある
・業務知識をもっているジャンルで小さいものから入るとよい
・勉強会で築く人と人との繋がりは大事
・35歳からでも本当に働きたいという強い意思があればいける
あとはプログラミングの適性が必要
お金
・月によるがMAX100万円/月
・自分の見積もり書をつくる時は要件からタスク分解して時間見積もりをする
・税金は高いため、経費申請とか節税対策はしている
・報酬は対面で交渉する
・育成費用や福利厚生など会社が負担してくれるお金を加味すると必ずしもフリーランスがいいわけではない
スキル
・言語は1つに絞ってまずはそれをマスターして自信を付けた方がよい
・はじめはC言語でやってたが、遅いのでMS-DOS 86アセンブラ書いていた
・基本はC#、データ処理はPhython、WebはJavaScript
・最初はRuby on Rails、今は機械学習を使うのでPhython
RubyはWebサイト作るまで楽だし、Phythonに似ているので入りやすい
・C言語はコンピュータの仕組みが透けて見える
・Techがvisualだと楽しいので、Javasciptはオススメ
・Javasctiptは言語としてみるといい言語ではないと思う
・同じ言語でも日々進化するため、再学習は忘れてはいけない
・いかに早くコードをかけるかを伸ばすこと
他人が書いているところを見るのと、ペアプロを行う
・Progateとdotインストールの違いはちゃんと教えてくれる人がいること
・資格よりも実力が問われることが多い
・同じスキルの人はごまんといるので人間力も大切
・スキルシフトの時はチュートリアルをやりきる、技術書を写経するくらい再学習
所感
・フリーエンジニアの方はIT技術が好きだからこそ生き生きとやれている
・フリーで稼ぎたい、IT技術が好きといった強い意志があることが大事
・マイペースで取り組めてワークライフバランスがとれることもモチベーション維持のポイント
・司会の方のファシリテーションがいまいち・・
・登壇者の方は経験に基づく話を丁寧にしてくれていて、エンジニアとしてよい刺激をもらえた
【忘却のJava#4】組み合わせ最適化問題を解くプログラムをJavaで書く(1)
今回は大学時代に研究書いていたC言語のコードをJavaで書いてみたいと思います。
その前にC言語で当時のプログラムを動かすところまで事前準備でやっておきます。
実際にJavaコード書くのは次回の予定です。
目次
組み合わせ最適化問題とは?
ある問題において、ある制約の下で選べる組み合わせの中で、最良の組み合わせを選ぶ問題です。
例えば、大きさや重さといった制約のもとナップサックに荷物を詰めるナップサック問題があります。
【参考】
「組合せ最適化問題とは」
最小全域木問題 (Minimum Spanning Tree Problem)
組み合わせ最適化問題の一つとして最小全域木問題があります。
全域木とは与 えられた重み付き無向グラフ中の頂点全てを含むような木のことです。
その全域木の中でも各辺の重みの和が最小となるものが最小全域木です。
【参考】
全域木とは:全域木 - Wikipedia
最小全域木とは:例えば数のようなものが最小全域木です。

Kruskalのアルゴリズム
最小全域木の最適解を導くことができるアルゴリズムのうちの1つです。
その時点で最も重みの小さい辺を閉路ができないように追加していき、部分木を順次拡大させていくことで最終的には最小全域木になるといったものです。
詳しくは以下の【参考】をみてみてください。
【参考】
クラスカル法 - Wikipedia
これを題材にしてC言語で書いたものをJavaで書いてみようと思ってます。
今回はその前に昔を思い出しながらCで書いたプログラムを実行するところまでやってみます。
Cのコード
久しぶりにCのコード見ましたが、printf()とかputs()が懐かしい。。
あとQuickSortをちゃんと書いてるのとか軽く感動。。
Kruskalの中ではUnion-Findというロジックを使ってます。
面白い手法なので興味ある人は以下の方のサイトとか参考にしてみてください。
【参考】
最小全域木(クラスカル法とUnionFind) - アルゴリズム講習会
graph.c
#include<stdio.h> #include<stdlib.h> #include"graph.h" #define min(x,y) ( x < y ? x : y ) #define max(x,y) ( x > y ? x : y ) /* rerutn empty graph(node number = n) */ Graph EmptyGraph(int n) { Graph g; int i, j; g.ord = n; g.adj = (int**)malloc(sizeof(int*) * n); for (i = 0; i < n; ++i) { g.adj[i] = (int*)malloc(sizeof(int) * n); } for (i = 0; i < n; i++) { for (j = 0; j < n; j++) { g.adj[i][j] = 0; g.adj[j][i] = 0; } } return g; } /* free graph array */ void FreeGraphArray(Graph g) { int i; for (i = 0; i < g.ord; i++) { free(g.adj[i]); g.adj[i] = NULL; } free(g.adj); g.adj = NULL; } /* make graph from m[] */ Graph ArraytoGraph(Graph g, int (*m)[g.ord]) { int i, j; for (i = 0; i < g.ord; i++) { for (j = 0; j < g.ord; j++) { g.adj[i][j] = m[i][j]; } } return g; } /* Print Graph g */ void PrintWeightedGraph(Graph g) { int i, j; for (i = 0; i < g.ord; i++) { for (j = 0; j < g.ord; j++) { printf("%4d", g.adj[i][j]); } puts(""); } } /* return total edge number of Graph g */ int CountEdge(Graph g) { int i, j; int s = 0; for (i = 0; i < g.ord; i++) { for (j = i + 1; j < g.ord; j++) { if (g.adj[i][j] > 0) { s++; } } } return s; } /* return parent of x */ Group *FindParent(Group *x) { if (x->parent != x) { x->parent = FindParent(x->parent); } return x->parent; } /* marge x and y */ void Union(Group *x, Group *y) { if (x->rank > y->rank) { y->parent = x; y->rank = x->rank; } else { x->parent = y; x->rank = y->rank; if (x->rank == y->rank) { y->rank++; x->rank++; } } } /* swap x and y */ void swap(Edge *x, Edge *y) { Edge temp; temp = *x; *x = *y; *y = temp; } /* Quick Sort */ void QuickSortEdge(Edge *e, int low, int high) { int i, j, mid; double pivot; mid = (low + high) / 2; i = low; j = high; pivot = e[mid].w; while(1) { while(e[i].w < pivot) { i++; } while(e[j].w > pivot) { j--; } if (i >= j) { break; } swap(&e[i++], &e[j--]); } if (low < i-1) { QuickSortEdge(e, low, i-1); } if (j+1 < high) { QuickSortEdge(e, j+1, high); } } /* make minimum spanning tree */ Graph Kruskal(Graph g, Graph tree) { int i, j, k, a, b, edge_num, cn_comp = 0; Group *flm; Edge *ed; edge_num = CountEdge(g); //Group *flagment; ed = (Edge *)calloc(edge_num, sizeof(Edge)); // add edge in set k = 0; for (i = 0; i < g.ord; i++) { for (j = i+1; j < g.ord; j++) { if (g.adj[i][j] > 0) { ed[k].w = MakeWeightValue(g.adj[i][j], i, j); ed[k].p1 = i; ed[k].p2 = j; k++; } } } flm = (Group *)malloc(sizeof(Group) * g.ord); for (i = 0; i < g.ord; i++) { flm[i].parent = &flm[i]; flm[i].rank = 0; flm[i].id = i; } QuickSortEdge(ed, 0, edge_num-1); k = 0; while (cn_comp < g.ord - 1) { a = ed[k].p1; b = ed[k].p2; // find if cycle exists or not if (FindParent(&flm[a]) != FindParent(&flm[b])) { // add edge in MST tree.adj[a][b] = g.adj[a][b]; tree.adj[b][a] = g.adj[b][a]; // marge set Union(flm[a].parent, flm[b].parent); cn_comp++; } k++; } free(flm); flm = NULL; free(ed); ed = NULL; return tree; } /* return sum of tree's edge consts */ int TreeTotalEdgeCost(Graph g) { int i, j, cost, sum = 0; for (i = 0; i < g.ord; i++) { for (j = i + 1; j < g.ord; j++) { cost = g.adj[i][j]; if (cost > 0) { sum += cost; } } } return sum; } /* return no duplicate weight value */ int MakeWeightValue(int w, int id, int p) { int value; int a, b, c; a = w * 100000; b = max(id, p) * 1000; c = min(id, p); value = a + b + c; return(value); }
main_mst.c
#define N 6 // graph node number #include<stdio.h> #include "graph.h" int main(void) { Graph g, tree; // graph int tc; // total cost // make graph g = EmptyGraph(N); tree = EmptyGraph(N); // test data int maze[N][N] = { { 0, 7,15, 0, 0, 0 }, { 7, 0,12, 6, 0, 0 }, {15,12, 0,18,17, 2 }, { 0, 6,18, 0,13, 0 }, { 0, 0,17,13, 0,24 }, { 0, 0, 2, 0,24, 0 }, }; // show test data g = ArraytoGraph(g, maze); puts("Graph (problem)"); PrintWeightedGraph(g); // make MST by Kruskal Method tree = Kruskal(g, tree); puts(""); puts("Tree (result)"); PrintWeightedGraph(tree); // show result tc = TreeTotalEdgeCost(tree); printf("total cost:%d\n", tc); // close graph FreeGraphArray(g); FreeGraphArray(tree); return(0); }
make
# make gcc -g -Wall -O2 -c main_mst.c gcc -o mst main_mst.o graph.o
実行結果
こんな感じで最適解を求めることができます。
この"Graph"問題の最小全域木は"Tree"で最小の重みは40という結果です。
# ./mst Graph (problem) 0 7 15 0 0 0 7 0 12 6 0 0 15 12 0 18 17 2 0 6 18 0 13 0 0 0 17 13 0 24 0 0 2 0 24 0 Tree (result) 0 7 0 0 0 0 7 0 12 6 0 0 0 12 0 0 0 2 0 6 0 0 13 0 0 0 0 13 0 0 0 0 2 0 0 0 total cost:40
以上。
【忘却のJava#3】sarの出力結果をExcelで扱いやすいように加工するプログラム
数が少ないうちはいいのですが、複数のファイルを何回も繰り返しExcelに食わせたりしていると、その度に手動で加工するのが大変なので自動化します。
SIerさんはLinuxサーバから取得した情報って、どうせWindows環境でExcelでまとめるのでPowershellで全然問題ないのですが、あくまでJavaのお勉強ということで。
やりたいこと
sarの出力結果を加工して、Excelで扱いやすいようにする
加工対象とするsar出力結果
前回書いた「sarコマンドによるLinuxのリソース情報取得方法」のコマンドで取得できる情報を加工対象とします。
例:CPU情報(「sar -u 1 30 | egrep -v 'Average:'」の出力結果)
Linux 3.10.0-957.el7.x86_64 (localhost.localdomain) 04/06/2019 _x86_64_ (2 CPU) 05:28:12 AM CPU %user %nice %system %iowait %steal %idle 05:28:13 AM all 0.00 0.00 0.00 0.00 0.00 100.00 05:28:14 AM all 0.00 0.00 0.50 0.00 0.00 99.50 (~省略~) 05:28:34 AM CPU %user %nice %system %iowait %steal %idle 05:28:35 AM all 0.00 0.00 0.50 0.00 0.00 99.50 05:28:36 AM all 0.00 0.00 0.00 0.00 0.00 100.00 05:28:37 AM all 0.00 0.00 0.00 0.00 0.00 100.00 (~省略~) 05:28:56 AM CPU %user %nice %system %iowait %steal %idle 05:28:57 AM all 0.00 0.00 0.00 0.00 0.00 100.00 05:28:58 AM all 0.00 0.00 0.00 0.00 0.00 100.00 05:28:59 AM all 0.00 0.00 0.50 0.00 0.00 99.50 (~省略~)
これをtxt形式でプログラムから読み込むこととします。
どのように加工するのか
(1) 時刻のヘッダが時刻(「04:56:45 AM」みたいに)
⇒ヘッダの文字列を時刻ではなく"TIME"に置換する
(2)ヘッダ行(CPU %user ~)のとスペース行が繰り返し表示される
⇒先頭行のヘッダだけ残し、それ以外は削除する
上記はメモリもディスクもネットワークも共通的に加工可能です。
Javaコード
久しぶりにまともにコードを書きました。
ファイルを読み込んで上記の加工処理をして、別のファイルに書き込む感じです。
ひとまず動けばいいのでえいやーです。
Emacsで書いてみましたが、キーバインドを忘れまくっててショック・・・
import java.io.*; import java.nio.file.*; import java.util.regex.*; import java.io.IOException; class EditSar { public static void main(String args[]) { try { // 書き込み用のファイルを作成 File outputfile = new File("./sar-cpu_after.txt"); outputfile.createNewFile(); Path outputpath = outputfile.toPath(); // 読み込み用のファイルをオープン Path inputpath = Path.of("./sar-cpu_before.txt"); String text = Files.readString(inputpath); BufferedReader reader = new BufferedReader(new StringReader(text)); //処理開始メッセージ System.out.println("加工処理を開始しました。"); // 読み込んだtxtファイルを1行ずつ処理 int emptycnt = 0; Boolean nextempty = false; String line = null; while ((line = reader.readLine()) != null) { // 空行だったら、書き込まない if (line.isEmpty()) { emptycnt++; nextempty = true; } else { // 空行の次の行(ヘッダ行)だったら、書き込まない if (nextempty) { nextempty = false; // 最初のヘッダ行だけは書き込む if (emptycnt == 1) { String newline = null; // 時刻を"TIME"という文字列に置換 newline = line.replaceAll("[0-9][0-9]:[0-9][0-9]:[0-9][0-9] [A-Z][A-Z]","TIME"); Files.writeString(outputpath, newline + "\r\n", StandardOpenOption.APPEND); } } else { // 除外対象となっていない行を書き込む Files.writeString(outputpath, line + "\r\n", StandardOpenOption.APPEND); } } } reader.close(); //処理終了メッセージ System.out.println("加工処理が終了しました。"); } catch (IOException e) { System.out.println(e); } } }
実行結果
[root@localhost 20190409_sar]# java EditSar 加工処理を開始しました。 加工処理が終了しました。
加工した結果 (sar-cpu_after.txt)
ヘッダを"TIME"に置換できました。
長くなるので省略していますが、繰り返しのヘッダも除外できてます。
あとはこれをExcelにtxtファイルとして読み込んで区切り位置を指定すればキレイに表にできます。
その後はピボットにするなり煮るなり焼くなり何なりと。
[root@localhost 20190409_sar]# cat sar-cpu_after.txt Linux 3.10.0-957.el7.x86_64 (localhost.localdomain) 04/06/2019 _x86_64_ (2 CPU) TIME CPU %user %nice %system %iowait %steal %idle 05:28:13 AM all 0.00 0.00 0.00 0.00 0.00 100.00 05:28:14 AM all 0.00 0.00 0.50 0.00 0.00 99.50 05:28:15 AM all 0.00 0.00 0.00 0.00 0.00 100.00 (~省略~) 05:29:08 AM all 0.00 0.00 0.00 0.00 0.00 100.00 05:29:09 AM all 0.00 0.00 0.50 0.00 0.00 99.50 05:29:10 AM all 0.00 0.00 0.00 0.00 0.00 100.00 05:29:11 AM all 0.00 0.00 0.00 0.00 0.00 100.00 05:29:12 AM all 0.00 0.00 0.00 0.00 0.00 100.00
以上。